【AWS/Athena】WAF のログ解析でパーティション射影を使ったテーブルの作り方

目次
はじめに
こんにちは!
7月でインフラエンジニアとして働き始めて早一年が経ち、晴れて二年目になったのも四か月前、そろそろ三年目の扉が見えてきたミコトです。
今回は最近触った Athena での WAF のログ解析の際、主にパーティション射影を使ったテーブルの作成でてこずったので、今回はそれについての記事を書いてみました。
※そもそも Athena ってどうやって使うの?テーブルって何?という方には向かない内容となりますのでご了承ください。
Amazon Athena(アマゾン アテナ)とは
ギリシャ神話で出てくる知恵と戦争の女神、、の話ではないですよ!
Amazon Athena は、S3 の中に保存されているデータを直接分析することができるクエリサービスです。
例えば、Elastic Load Balancer や Cloud Front 、WAF 等 S3 へのログ出力をオンにしていても、膨大な量のログの中から分間リクエスト数や特定のアクセス元 IP を特定しようと思ったとき、わざわざテキストファイルをダウンロードしてローカルで解析するのは手間ですよね?
そんな時に、Amazon Athena を使用すれば、手元にログファイルを落とすことなくコンソール上でのクエリ実行だけでログの解析が可能です!!
もっと詳しく知りたい方は、ぜひドキュメントをご一読ください。
実行環境について
今回は以下のような構成でクエリの実行をしています。
構成によっては後に指定する S3 のパスが変わってきますのでご注意ください。
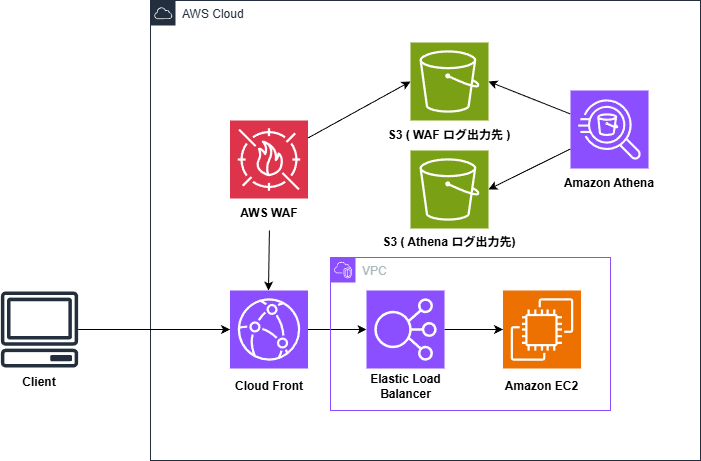
使用した S3 の階層構造は以下のようになっています。

テーブルの作成
今回はこちらを参考に、テーブルを作成していきます。
先述の通り、CloudFront が最前段にいるので、S3 のパスに /cloudfront が含まれます。
CREATE EXTERNAL TABLE `waf_logs_partition_projection`(
`timestamp` bigint,
`formatversion` int,
`webaclid` string,
`terminatingruleid` string,
`terminatingruletype` string,
`action` string,
`terminatingrulematchdetails` array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>,
`httpsourcename` string,
`httpsourceid` string,
`rulegrouplist` array<struct<rulegroupid:string,terminatingrule:struct<ruleid:string,action:string,rulematchdetails:array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>>,nonterminatingmatchingrules:array<struct<ruleid:string,action:string,overriddenaction:string,rulematchdetails:array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>,challengeresponse:struct<responsecode:string,solvetimestamp:string>,captcharesponse:struct<responsecode:string,solvetimestamp:string>>>,excludedrules:string>>,
`ratebasedrulelist` array<struct<ratebasedruleid:string,limitkey:string,maxrateallowed:int>>,
`nonterminatingmatchingrules` array<struct<ruleid:string,action:string,rulematchdetails:array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>,challengeresponse:struct<responsecode:string,solvetimestamp:string>,captcharesponse:struct<responsecode:string,solvetimestamp:string>>>,
`requestheadersinserted` array<struct<name:string,value:string>>,
`responsecodesent` string,
`httprequest` struct<clientip:string,country:string,headers:array<struct<name:string,value:string>>,uri:string,args:string,httpversion:string,httpmethod:string,requestid:string,fragment:string,scheme:string,host:string>,
`labels` array<struct<name:string>>,
`captcharesponse` struct<responsecode:string,solvetimestamp:string,failurereason:string>,
`challengeresponse` struct<responsecode:string,solvetimestamp:string,failurereason:string>,
`ja3fingerprint` string,
`ja4fingerprint` string,
`oversizefields` string,
`requestbodysize` int,
`requestbodysizeinspectedbywaf` int)
PARTITIONED BY (
`log_time` string
)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://{WAF のログ出力先のバケット}/AWSLogs/{アカウントID}/WAFLogs/cloudfront/{対象CF}/'
TBLPROPERTIES(
'projection.enabled' = 'true',
'projection.log_time.type' = 'date',
'projection.log_time.range' = '2025/11/01/00/00,NOW',
'projection.log_time.format' = 'yyyy/MM/dd/HH/mm',
'projection.log_time.interval' = '1',
'projection.log_time.interval.unit' = 'minutes',
'storage.location.template' = 's3://{WAF のログ出力先のバケット}/AWSLogs/{アカウントID}/WAFLogs/cloudfront/{対象CF}/${log_time}')
※ALB 等のリージョンリソースに適用している場合はここが /ap-northeast-1/(東京リージョンの場合)などのリージョン名になるので注意してください
※今回の構造では yyyy/MM/dd/HH/mm となっていますが、お使いの S3 階層構造によっては変更が必要な可能性があります。もし yyyy/MM/dd/HH の場合、projection.log_time.interval.unit を hours に変更する必要があります。
パーティション射影について
本題にあるパーティション射影とは、パーティション管理を自動化してクエリパフォーマンスを向上させる機能です。
( ^ω^)<日本語でおk
そんな顔をしないでください。
これから説明していきます。
テーブル作成クエリの中だと、以下がまさにそれにあたります。
こちらのクエリでは、2025/11/01 以降から現在までのログを指定しています。
PARTITIONED BY (
`log_time` string
)
~省略~
TBLPROPERTIES(
'projection.enabled' = 'true',
'projection.log_time.type' = 'date',
'projection.log_time.range' = '2025/11/01/00/00,NOW',
'projection.log_time.format' = 'yyyy/MM/dd/HH/mm',
'projection.log_time.interval' = '1',
'projection.log_time.interval.unit' = 'minutes',
'storage.location.template' = 's3://{WAF のログ出力先のバケット}/AWSLogs/{アカウントID}/WAFLogs/cloudfront/{対象CF}/${log_time}')
S3 バケット内のログファイルの配置は 年/月/日/時/分 のように階層構造になっていますよね?それをパーティションで区切られているという言い方をします。
通常は、AWS Glue Data Catalog に対してパーティションがどこにあるかをコマンドを定期実行して登録する必要があります。
┌[ ∵]┐ <新しいデータ増えた?場所何処にあるん?
というようなやりとりを Glue と毎回行わないといけません。
そのパーティションの階層構造を事前に Athena に教えてあげることで、Athena はもらった階層構造の情報を元に自動的にログデータが置かれている場所を計算してくれます。
そうすることで、新規追加されたパーティションも自動で把握してくれるので、わざわざ解析させるログデータの範囲が増えるたびに AWS Glue Data Catalog を読ませる必要がなくなります。
└[ ∵]┘ <こういう階層構造でデータ保存されてるなら、新規ログはここに来るやろ
みたいな感じです。
これをパーティション射影と言います。
書き方について
次に、実際の動きはわかったとしてどういう風に書いていけばいいの?
というところを解説していきます。
PARTITIONED BY (
`log_time` string
)
~省略~
TBLPROPERTIES(
'projection.enabled' = 'true',
'projection.log_time.type' = 'date',
'projection.log_time.range' = '2025/11/01/00/00,NOW',
'projection.log_time.format' = 'yyyy/MM/dd/HH/mm',
'projection.log_time.interval' = '1',
'projection.log_time.interval.unit' = 'minutes',
'storage.location.template' = 's3://{WAF のログ出力先のバケット}/AWSLogs/{アカウントID}/WAFLogs/cloudfront/{対象CF}/${log_time}')
先ほども登場したこちらですが、主に PARTITIONED と TBLPROPERTIES の二つの句を使います。
PARTITIONED:
パーティションキーを指定します。
ここでは、log_time という名前のキーを使用していますが他のキーも設定可能です。
既存のカラム名と被ると Athena が混乱してエラーを吐くかもしれないので、基本的には元のログデータの中には存在しない名前に設定してくださいね。
TBLPROPERTIES:
パーティション射影の有効化設定と、指定されたキーに対する形式の詳細設定を指定します。
今回は、log_time の中に含まれている情報を整理して Athena に教えてあげている感じですね。
projection.enabled: 「パーティション射影使うよ!」という宣言type: データの種類(今回は日付なので date)range: データの「始まり」と「終わり」の範囲。NOW を使うとクエリを実行したその瞬間までを範囲にしてくれるので非常に便利ですformat: S3のフォルダ名がどういう形式か(yyyy/MM/dd など)interval: データの増える間隔(1分ごとなら 1)storage.location.template: 計算した値を S3 パスのどこに当てはめるか。${log_time} の部分に Athena が計算した日付を当てはめる
このときの注意点なのですが、PARTITIONED と TBLPROPERTIES で指定するパーティションキーの値が異なると以下のようなエラーが発生しますので必ず合わせるように書きます。
INVALID_TABLE_PROPERTY: Table {{データベース名}}.{{テーブル名}} is configured for partition projection, but the following partition columns are missing projection configuration: [year, month, day, hour]
このクエリは、クエリで修飾されていない限り、「{{データベース名}}」データベースに対して実行されました。エラーメッセージを フォーラム に投稿するか、クエリ ID: XXXX とともに カスタマーサポート にお問い合わせください。
※勉強不足だった当時の筆者は別々の値を書いて詰まりました。。
また、本記事では storage.location.template の値が CloudFront を使用した場合のパスになっています。
LB に WAF が紐づいている場合は、以下のようなパスになるのでご注意ください。
LOCATION
's3://{WAF のログ出力先のバケット}/AWSLogs/{アカウントID}/WAFLogs/ap-northeast-1(リージョン)/{対象WAF}/'
~省略~
'storage.location.template' = 's3://{WAF のログ出力先のバケット}/AWSLogs/{アカウントID}/WAFLogs/${region}/{対象WAF}/${log_time}')
クエリを実行する
ここまででテーブルの作成についての解説は終わりとして、最後に作ったテーブルを使用してみましょう!
先ほど指定したパーティションキーの log_time を使ってデータのスキャンをしてみます。
SELECT
from_unixtime(timestamp/1000, 'Asia/Tokyo') AS JST, *
FROM waf_logs_partition_projection
WHERE
log_time BETWEEN '2025/11/16/00/00' AND '2025/11/16/00/59';
※yyyy/MM/dd/HH/ に沿ったフォーマットの場合は 2025/11/16/00/ のように変更してください
ここでログデータが出力されていれば設定完了です🎉🎉
この実行時に値が取れなかった場合は、以下を確認してみてください!
- パーティションキーの設定がうまく行っているか
storage.location.templateで指定しているパスに誤りがないか
おわりに
いかがでしたでしょうか。
ログ解析用のクエリ自体に問題はなかったものの、テーブル作成の段階でかなりてこずったのでもう少しちゃんと勉強して記事にしてみました。
先輩や AI に聞きながらやっていた部分を、ゆっくりドキュメントを読みつつブログに起こしてみてかなり勉強になりました!!
この記事が皆様のお役に立てれば幸いです。
引き続きよろしくお願いします!
参考
Athena のパーティション射影(Partition Projection)を理解するためにイメージ図を書いた
パーティション化とは
Amazon Athena でパーティション射影を使用する
パーティション射影を使用して Athena で AWS WAF S3 ログ用テーブルを作成する
パーティションキーの選択方法
 22
22 この記事をかいた人
About the author


