[AWS/Athena] 如何使用分区投影创建用于 WAF 日志分析的表

介绍
大家好!
我从七月份开始担任基础设施工程师,到现在已经一年了,四个月前我正式成为了一名二年级员工。现在,我的第三年也指日可待了。
这次,我写了一篇文章,讲述了我最近使用Athena分析 WAF 日志的经验,其中我主要在使用分区投影创建表时遇到了困难。
*请注意,本文不适合不熟悉 Athena 使用方法或不了解表格概念的人士阅读。
什么是亚马逊雅典娜?
这与希腊智慧和战争女神无关! Amazon Athena是一项查询服务,可让您直接分析存储在 S3 中的数据。
例如,即使您已使用 Elastic Load Balancer、Cloud Front、WAF 等启用了日志输出到 S3,但当您想要从大量日志中识别每分钟的请求数或特定的访问源 IP 地址时,下载文本文件并在本地进行分析可能会很麻烦,对吗?
在这种情况下,Amazon Athena允许您通过在控制台上执行查询来分析日志,而无需将日志文件下载到本地计算机!更多详情,请阅读文档。
关于执行环境
在本示例中,查询使用以下配置执行。请注意,稍后指定的S3 路径 可能会根据您的配置而有所不同。
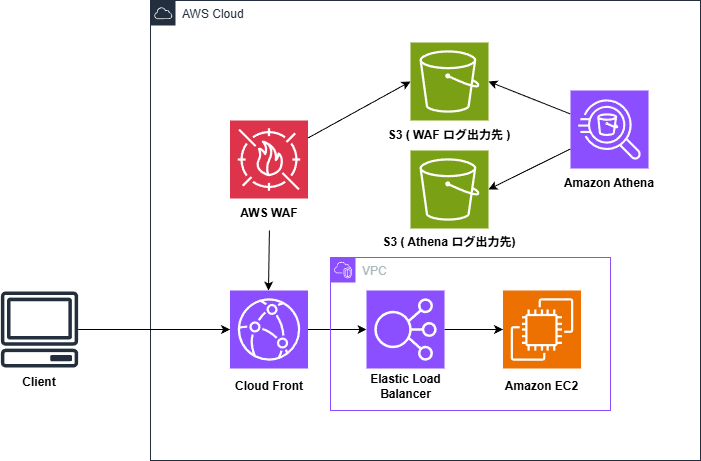
所使用的S3层级结构如下:

创建表格
这次以此创建表
如前所述,CloudFront 处于最前端,因此 S3 路径将包含 /cloudfront。
创建外部表 `waf_logs_partition_projection`( `timestamp` bigint, `formatversion` int, `webaclid` string, `terminatingruleid` string, `terminatingruletype` string, `action` string, `terminatingrulematchdetails` array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>, `httpsourcename` string, `httpsourceid` string, `rulegrouplist` array<struct<rulegroupid:string,terminatingrule:struct<ruleid:string,action:string,rulematchdetails:array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>>,nonterminatingmatchingrules:array<struct<ruleid:string,action:string,overriddenaction n:string,rulematchdetails:array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>,challengeresponse:struct<responsecode:string,solvetimestamp:string>,captcharesponse:struct<responsecode:string,solvetimestamp:string>>>,excludedrules:string>>,`ratebasedrulelist` array<struct<ratebasedruleid:string,limitkey:string,maxrateallowed:int>>,`nonterminatingmatchingrules` array<struct<ruleid:string,action:string,rulematchdetails:array<struct<conditiontype:string,sensitivitylevel:string,location:string,matcheddata:array<string>>>,challengeresponse:struct<responsecode:string,solvetimestamp:string>,captcharesponse:struct<responsecode:string,solvetimestamp:string>>>, `requestheadersinserted` array<struct<name:string,value:string>>, `responsecodesent` string, `httprequest` struct<clientip:string,country:string,headers:array<struct<name:string,value:string>>,uri:string,args:string,httpversion:string,httpmethod:string,requestid:string,fragment:string,scheme:string,host:string>, `labels` array<struct<name:string>>, `captcharesponse` struct<responsecode:string,solvetimestamp:string,failurereason:string>, `challengeresponse` struct<responsecode:string,solvetimestamp:string,failurereason:string>, `ja3fingerprint` string, `ja4fingerprint` string, `oversizefields` string, `requestbodysize` int, `requestbodysizeinspectedbywaf` int) PARTITIONED BY ( `log_time` string ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://{WAF TBLPROPERTIES( 'projection.enabled' = 'true', 'projection.log_time.type' = 'date', 'projection.log_time.range' = '2025/11/01/00/00,NOW', 'projection.log_time.format' = 'yyyy/MM/dd/HH/mm', 'projection.log_time.interval' = '1', 'projection.log_time.interval.unit' = 'minutes', 'storage.location.template' = 's3://{WAF 日志输出存储桶}/AWSLogs/{账户 ID}/WAFLogs/cloudfront/{目标 CF}/${log_time}')
*请注意,如果您将此配置应用于区域资源(例如 ALB),则此处应填写区域名称,例如 /ap-northeast-1/(代表东京区域)。 * 在此结构中,时间格式为yyyy/MM/dd/HH/mm ,但根据您的 S3 层级结构,可能需要进行更改。如果时间格式为yyyy/MM/dd/HH ,则需要将projection.log_time.interval.unit更改为 hours。
关于分区投影
主题“分区投影”是一项能够自动管理分区以提高查询性能的功能。
(^ω^) <日语可以
别摆出那副表情。
我现在就解释。
以下是一个在表创建查询中的完美示例。
此查询指定从 2025 年 11 月 1 日至今的日志。
按 (`log_time` 字符串) 分区 ~省略~ TBLPROPERTIES( 'projection.enabled' = 'true', 'projection.log_time.type' = 'date', 'projection.log_time.range' = '2025/11/01/00/00,NOW', 'projection.log_time.format' = 'yyyy/MM/dd/HH/mm', 'projection.log_time.interval' = '1', 'projection.log_time.interval.unit' = 'minutes', 'storage.location.template' = 's3://{WAF 日志输出目标存储桶}/AWSLogs/{账户 ID}/WAFLogs/cloudfront/{目标 CF}/${log_time}')
S3 存储桶中的日志文件是按层级结构排列的,例如年/月/日/小时/分钟,对吗?这称为分区。通常,您需要定期运行命令,将每个分区的位置注册到AWS Glue 数据目录中。
┌[ ∵]┐ <新增数据?数据位于何处?
每次使用胶水都必须经过这个过程。
通过预先向 Athena 提供分区层次结构,Athena可以根据接收到的层次结构信息自动计算日志数据所在的位置。
这样一来,新添加的分区就会被自动识别,从而无需在每次要分析的日志数据范围增加时手动读取 AWS Glue 数据目录。
└[ ∵]┘ <如果数据存储在此层次结构中,则新日志将出现在这里。
差不多就是这样。这叫做分区投影。
如何写作
接下来,假设你已经理解了实际流程,那么你应该如何编写代码呢?
我将解释这一点。
按 (`log_time` 字符串) 分区 ~省略~ TBLPROPERTIES( 'projection.enabled' = 'true', 'projection.log_time.type' = 'date', 'projection.log_time.range' = '2025/11/01/00/00,NOW', 'projection.log_time.format' = 'yyyy/MM/dd/HH/mm', 'projection.log_time.interval' = '1', 'projection.log_time.interval.unit' = 'minutes', 'storage.location.template' = 's3://{WAF 日志输出目标存储桶}/AWSLogs/{账户 ID}/WAFLogs/cloudfront/{目标 CF}/${log_time}')
如前所述,这主要使用两个短语: PARTITIONED和TBLPROPERTIES 。
PARTITIONED:
指定分区键。
这里我们使用名为 log_time 的键,但也可以设置其他键。
如果名称与现有列名冲突,Athena 可能会出错并抛出错误,因此通常设置一个原始日志数据中不存在的名称。
TBLPROPERTIES:
指定分区投影的启用/禁用设置以及指定键的详细格式化设置。
在本例中,它似乎正在整理 log_time 中包含的信息并将其提供给 Athena。
projection.enabled:声明“将使用分区投影!”类型:数据类型(在本例中为日期)范围:数据的范围,从开始到结束。使用 NOW 非常方便,因为它将范围设置为包含查询执行的时刻。格式:S3 文件夹名称采用什么格式(例如,yyyy/MM/dd)?间隔:添加数据的间隔(例如,1 表示每分钟添加一次)。storage.location.template:指定将计算值应用到 S3 路径中的哪个位置。将 ${log_time} 替换为 Athena 计算出的日期。
这里需要注意的一点是,如果PARTITIONED 和 TBLPROPERTIES 不同,则会发生以下错误,因此请务必将它们写入匹配项。
INVALID_TABLE_PROPERTY: 表 {{数据库名称}}.{{表名称}} 配置为分区投影,但投影配置中缺少以下分区列:[year, month, day, hour]
除非查询语句中另有限定,否则此查询将针对“{{数据库名称}}”数据库执行。请将错误信息发布到我们的论坛或联系客户支持,并提供查询 ID:XXXX。
*当时我学习不够,所以写了一些不同的值,结果卡住了。
此外,本文中 storage.location.template 是使用 CloudFront 时所用的路径。
请注意,如果 WAF 与负载均衡器关联,则路径将如下所示。
LOCATION 's3://{WAF 日志输出目标存储桶}/AWSLogs/{账户 ID}/WAFLogs/ap-northeast-1(区域)/{目标 WAF}/' ~省略~ 'storage.location.template' = 's3://{WAF 日志输出目标存储桶}/AWSLogs/{账户 ID}/WAFLogs/${区域}/{目标 WAF}/${日志时间}')
执行查询
至此,关于创建表的讲解就结束了。最后,让我们来试试刚刚创建的表!
我们将使用之前指定的分区键 `log_time` 来扫描数据。
SELECT from_unixtime(timestamp/1000, 'Asia/Tokyo') AS JST, * FROM waf_logs_partition_projection WHERE log_time BETWEEN '2025/11/16/00/00' AND '2025/11/16/00/59';
*如果使用yyyy/MM/dd/HH/格式,请将其更改为类似2025/11/16/00/ 的格式。
如果此处输出日志数据,则设置完成🎉🎉
如果在此执行过程中未能获取值,请检查以下内容!
- 分区键设置是否正确?
- 检查 storage.location.template 中指定的路径是否存在任何错误
。
结论
所以,你觉得怎么样?
日志分析查询本身没有问题,但我在创建表阶段遇到了很多麻烦,所以我更深入地研究了这个问题,并决定写一篇文章来谈谈它。
我通过慢慢阅读文档,并记下我操作的步骤,同时向我的前辈和人工智能寻求建议,并将这些内容发布在我的博客上,从中学习到了很多东西!
希望这篇文章对您有所帮助。
感谢您一直以来的支持!
参考
此图说明了如何理解 Athena 的分区投影。内容包括
:分区、
在 Amazon Athena 中使用分区投影
、使用分区投影创建用于 AWS WAF S3 日志的表,以及
如何选择分区键。
 44
44 这篇文章的作者
关于作者


