如何使用负载平均值和 Linux 进程来检查服务器负载
2016.02.04
 1
1 
我叫伊藤,是一名基础设施工程师。
服务器运维中最大的挑战之一就是负载突然增加。
“服务变慢了,但我不知道为什么!”
,我想解释一下“平均负载”的概念,这通常是大家首先要检查的指标。
关于平均负载
当系统负载过高导致网站或游戏运行缓慢时,首先应该做的就是使用 top 命令。top
命令可以实时显示操作系统当前的运行状态。
由于信息量很大,你可能不知道从何入手。
这次我们讨论的是平均负载,所以让我们来查看一下平均负载。
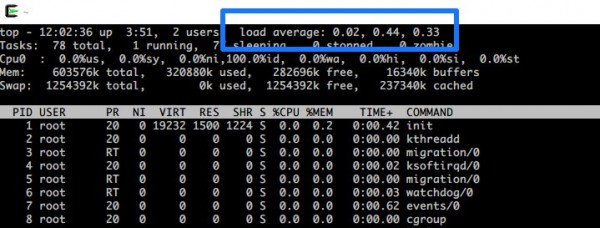
负载平均值 (LA) 代表服务器的“进程队列”,通常以 1 分钟、5 分钟或 15 分钟等时间段内的平均值显示。
上图中,从左到右依次为“1 分钟前的洛杉矶”、“5 分钟前的洛杉矶”和“15 分钟前的洛杉矶”。
各种进程都在请求 CPU 处理它们,但服务器无法处理所有进程,因此
这些进程正在排队等待处理。
平均负载越高,说明服务器负载越重。
服务器同时能够处理的进程数等于服务器上的CPU核心数。
服务器支持多任务处理,例如,一台四核服务器可以同时处理四个进程。
关于 Linux 进程
你现在对平均负荷有大致了解了吗?
现在我们来谈谈 Linux 进程,它们也具有不同的状态。
| 任务正在运行 | 该进程处于可执行状态,要么正在运行,要么正在等待执行。 |
|---|---|
| 任务可中断 | 可能会发生中断,但尚不清楚进程何时会返回,例如在等待用户输入时。 |
| 任务不可中断 | 服务器过载,无法中断,因此正在等待 |
| 任务已停止 | 中止状态 |
| 任务_僵尸 | 所谓的僵尸进程 |
参考资料:进程管理 1 - 进程描述符 - Pridact 信息共享 Wiki
参考资料:了解 Linux 的工作原理 - 进程管理和调度
其中,以下三种情况与负荷无关:
- TASK_INTERRUPTIBLE:此任务正在等待用户输入,因此未排队,因为不知道何时返回。
- TASK_STOPPED:进程已停止。
- TASK_ZONBIE:变成了僵尸
换句话说,剩下的两个任务会被排队,成为负载平均值,也就是“系统负载”。这可以是“
等待运行的任务(TASK_RUNNING)”,也可以是“高负载且无法中断的任务(TASK_UNINTERRUPTIBLE)”。
- 任务正在运行
- 任务不可中断
洛杉矶可以检查的其他命令
以下是另外两个可用于检查负载平均值的命令。
w 命令可以让你查看其他哪些用户已登录。
[root@test ~]# w 12:49:13 up 4:38, 2 users, load average: 0.00, 0.00, 0.00 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT vagrant pts/0 10.0.2.2 11:43 0.00s 0.00s 0.00s sshd: vagrant [priv] vagrant pts/1 10.0.2.2 11:55 54:08 2.06s 0.00s sshd: vagrant [priv]
uptime 命令可以让你查看服务器还能持续运行多久。
你也可以在这里查看平均负载。
[root@test ~]# 运行时间 12:49:34 运行时间 4:38,2 个用户,平均负载:0.00,0.00,0.00
概括
所以,这次我解释了负载平均值!
- 高负载时检查平均负载。
- 找出你的服务器无法处理的进程数。
- 平均负载越高,负载就越高。
- 虽然它被称为“过程”,但它有多种状态。
- 有多种命令可以用来查看平均负载。
如果我们能创建一个无需我们担心这些事情的系统,那就太好了,但在操作服务器时,了解这些值仍然非常重要,所以请确保您正确理解它们!
如果您想与云计算专业人士交谈
自成立以来,Beyond 一直利用我们作为多云集成商和托管服务提供商 (MSP) 所培养的技术能力,设计、构建和迁移使用各种云/服务器平台(包括 AWS、GCP、Azure 和 Oracle Cloud)的系统。
我们提供根据客户所需系统和应用程序的规格和功能进行优化的定制云/服务器环境,因此,如果您对云感兴趣,请随时与我们联系。
● 云/服务器设计与构建
● 云/服务器迁移
● 云/服务器运行、维护与监控(全年365天,每天24小时)
11 这篇文章的作者
关于作者


