![[大阪/横滨/德岛] 寻找基础设施/服务器端工程师!](https://beyondjapan.com/cms/wp-content/uploads/2022/12/recruit_blog_banner-768x344.jpg)
[大阪/横滨/德岛] 寻找基础设施/服务器端工程师!

【超过500家企业部署】AWS搭建、运维、监控服务

【CentOS的后继者】AlmaLinux OS服务器搭建/迁移服务
![[仅适用于 WordPress] 云服务器“Web Speed”](https://beyondjapan.com/cms/wp-content/uploads/2022/11/webspeed_blog_banner-768x344.png)
[仅适用于 WordPress] 云服务器“Web Speed”
![[便宜]网站安全自动诊断“快速扫描仪”](https://beyondjapan.com/cms/wp-content/uploads/2023/04/quick_eyecatch_blogbanner-768x345.jpg)
[便宜]网站安全自动诊断“快速扫描仪”
![[预约系统开发] EDISONE定制开发服务](https://beyondjapan.com/cms/wp-content/uploads/2023/06/edisone_blog_banner-768x345.jpg)
[预约系统开发] EDISONE定制开发服务
![[注册100个URL 0日元] 网站监控服务“Appmill”](https://beyondjapan.com/cms/wp-content/uploads/2021/03/Appmill_ブログバナー-768x344.png)
[注册100个URL 0日元] 网站监控服务“Appmill”

【兼容200多个国家】全球eSIM“超越SIM”
![[如果您在中国旅行、出差或驻扎]中国SIM服务“Choco SIM”](https://beyondjapan.com/cms/wp-content/uploads/2024/05/china-sim_blogbanner-768x345.jpg)
[如果您在中国旅行、出差或驻扎]中国SIM服务“Choco SIM”

【全球专属服务】Beyond北美及中国MSP
![[YouTube]超越官方频道“美由丸频道”](https://beyondjapan.com/cms/wp-content/uploads/2021/07/バナー1-768x339.jpg)
[YouTube]超越官方频道“美由丸频道”
[RDB] Cloud Spanner 概述和特性 [全球数据库]

我是技术销售部门的大原。
Google Cloud提供的 Cloud Spanner 的概述和功能
Cloud Spanner 概述和功能
Cloud Spanner是一项功能强大、完全托管的关系数据库服务。
提供自动同步复制,以实现全球范围内的事务一致性、架构、SQL(ANSI 2011 和扩展)、高可用性和灾难恢复 (DR)。
为云构建的企业级、全球分布式、高度一致的数据库服务,它利用关系数据库结构的优势,并水平扩展到数千个非关系节点。
Cloud Spanner 使用案例
使用 CloudSpanner 的案例场景有:
● 您拥有需要强一致性的关系数据。
● 您需要通过数据复制实现高可用性
。
● 您需要高可扩展性(从小规模开始,根据需要进行扩展。可以快速扩大规模。并超越传统关系型OLTP系统的规模限制。
云扳手架构
Cloud Spanner 是一个全球数据库,提供两种类型的配置:区域配置和多区域配置。
为了对数据进行逻辑分区并促进数据的正确复制和分片,CloudSpanner 使用实例和数据库。
① 实例和数据库
实例是指在该实例上创建的 Cloud Spanner 数据库使用的资源分配。
创建实例包括两个重要的选择:实例配置和节点数量。
实例配置定义该实例内数据库的地理位置和复制。
数据库是实例内表的集合。
Cloud Spanner 的数据库维护允许您读取和写入数据的表和索引。
一个实例可以有多个数据库。
● 区域实例
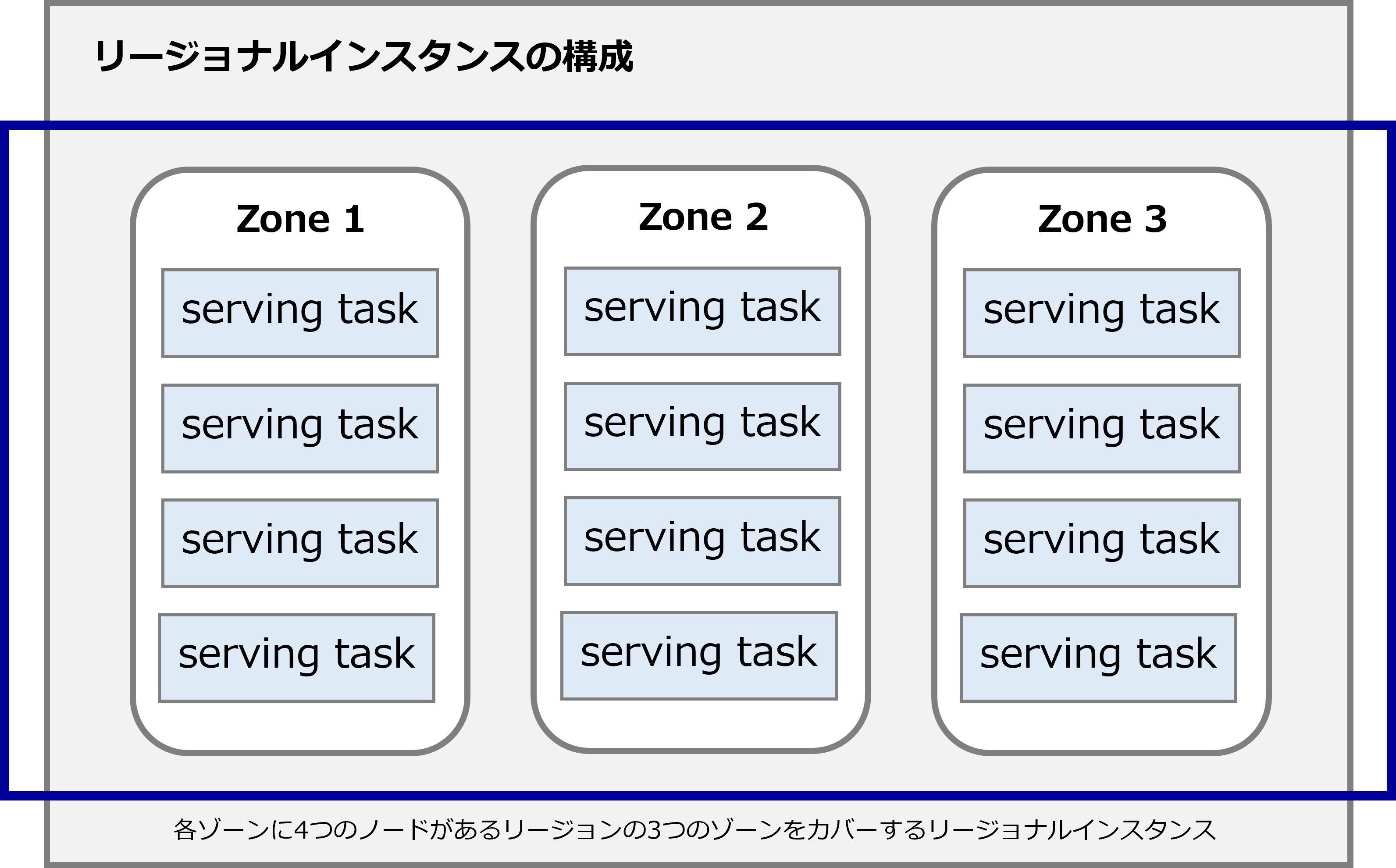
区域实例跨越单个 Google Cloud 区域。
在区域实例配置中,Cloud Spanner三个读/写副本,每个副本位于该区域的不同 Google Cloud 区域中。
每个读/写副本都包含生产数据库的完整副本,可以处理读/写和只读请求。
Cloud Spanner 在不同区域中使用副本,因此即使在单个区域发生故障时,您的数据库仍然可用。
● 多区域实例
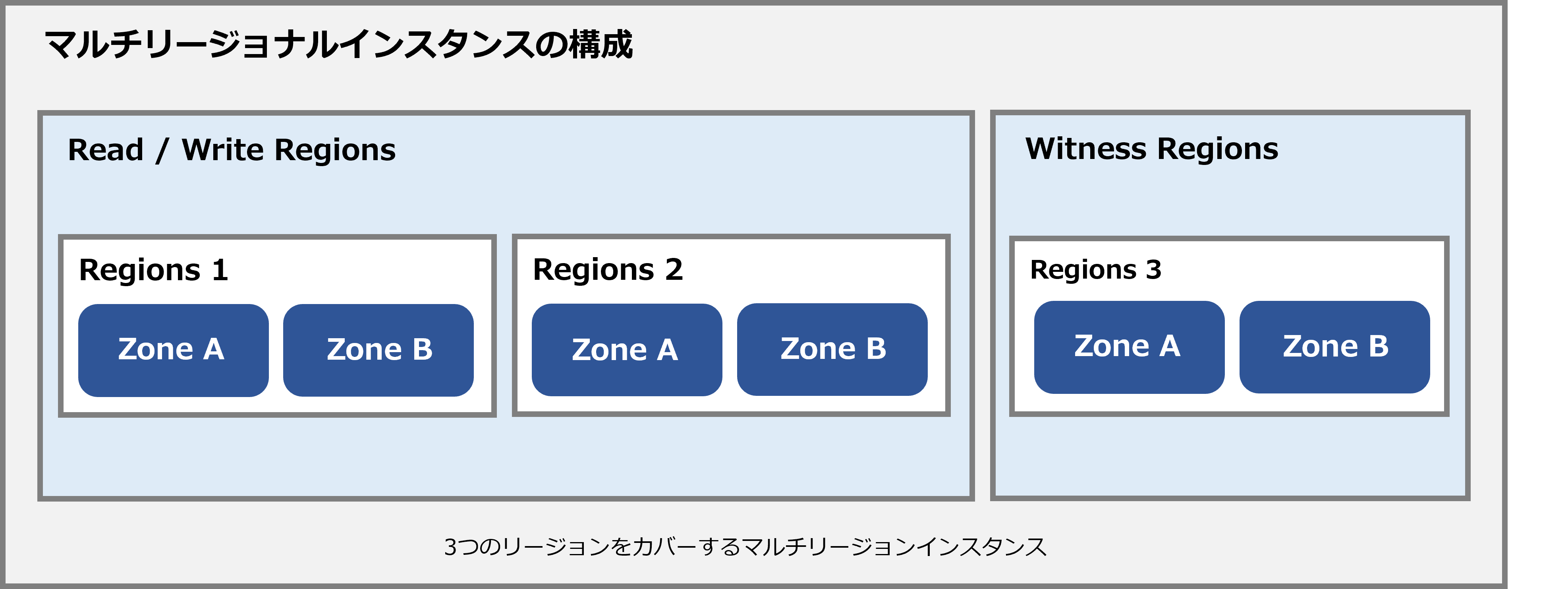
多区域配置允许您将数据库中的数据复制到多个区域以及跨多个区域的多个区域(如实例配置中所定义)。
这些额外的副本允许您从配置中的区域附近或区域内的多个位置以低延迟读取数据。
如果您有一个应用程序需要从多个地理位置读取数据,那么多区域实例非常有用,因为它允许您的应用程序在更多位置实现更快的读取,但代价是写入延迟略有增加。
每个多区域配置包括两个指定为读/写区域包含读/写副本这些读/写区域之一被指定为默认读取器区域。 (意味着它包含数据库的领导者副本)
* 在多区域配置中,仲裁(读/写)副本分布在多个区域中,这需要权衡,例如这些副本相互通信并在写入时进行投票时可能会出现额外的网络延迟。是。 (Cloud Spanner 要求提交至少保存在两个不同的区域,这会增加提交延迟)
② 高层架构
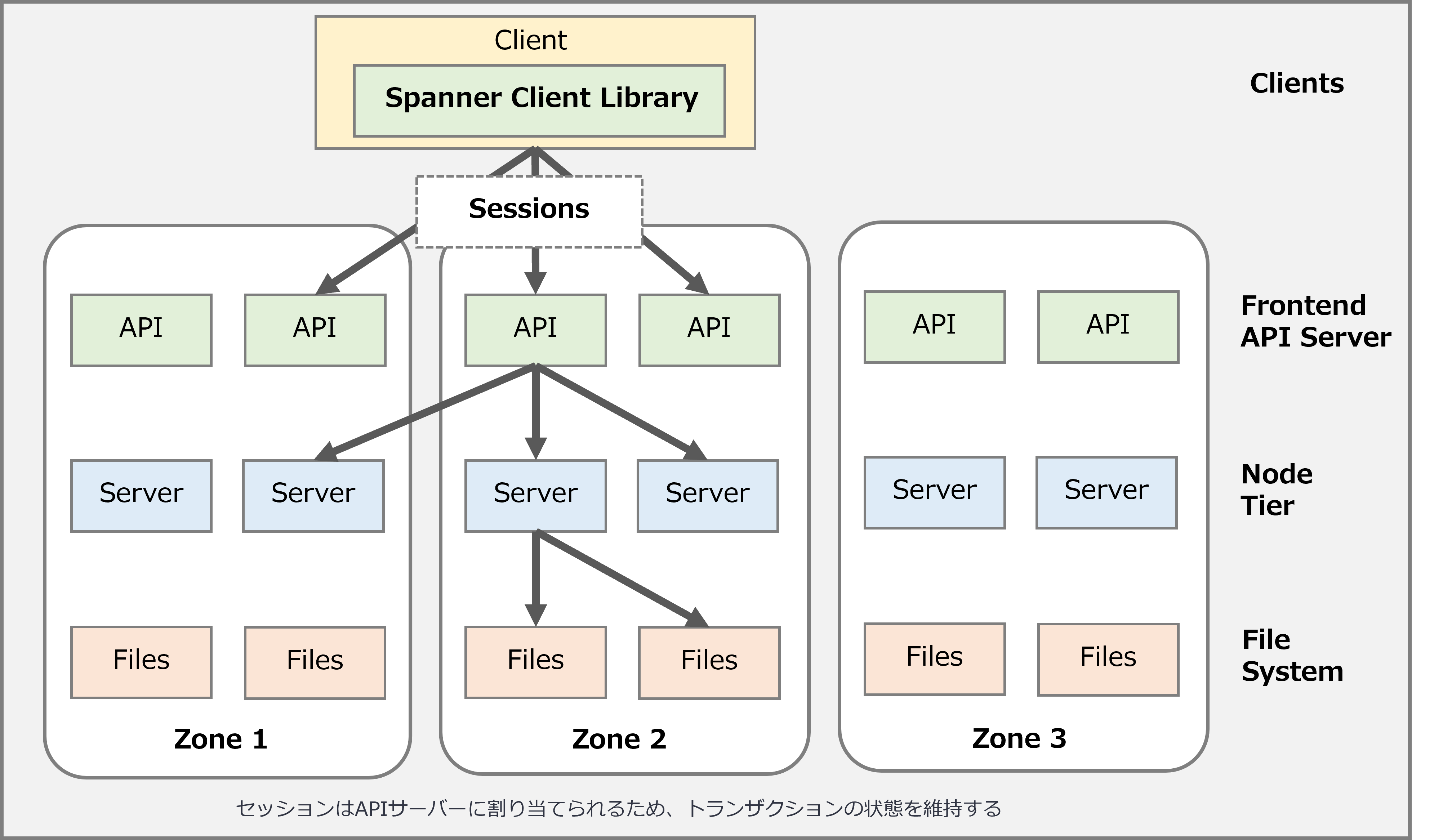 简单来说,Cloud Spanner 的功能主要是由
简单来说,Cloud Spanner 的功能主要是由
API 服务器您可以Cloud Spanner客户端库执行环境会话 (每个会话与一个数据库关联,一次只能运行一个事务)
会话被分配给 API 服务器,以便可以维护事务状态。
API服务器不是部署在可用区或地域级别,而是可以跨地域共享,可以是多地域的。
API服务器根据API请求确定联系哪个节点服务器来完成请求。
节点服务器是您分配给实例并执行大部分工作的节点。
节点服务器处理读取和写入/提交事务请求,但不存储数据。
数据存储在Google底层由其他存储节点提供的分布式文件系统中。
概括
我对使用 Cloud Spanner 的印象是,如果您是一家全球扩张的公司(在每个国家都有数据的公司),需要一致的数据处理和低网络延迟,那么您应该使用 Cloud Spanner 看起来值得一看。
 00
00 ![[2025.6.30 Amazon Linux 2 支持结束] Amazon Linux 服务器迁移解决方案](https://beyondjapan.com/cms/wp-content/uploads/2024/05/59b34db220409b6211b90ac6a7729303-1024x444.png)
[2025.6.30 Amazon Linux 2 支持结束] Amazon Linux 服务器迁移解决方案
写这篇文章的人
关于作者
