年末年始の勉強にピッタリ! GCP BigQuery に Datastore のデータを読み込んで解析してみる

こんにちは。
開発チームのワイルド担当、まんだいです。
Appmill (アプミル)の監視データの分析をしようと思ったのですが、それなりの量になってきて、DB に格納するのも一苦労なサイズになってきました。
こうなったら、GCP といえば、あれ。
そう、BigQuery の出番ですよね。
今回は、GCP 上にある Datastore のデータを BigQuery にインポートしてクエリを実行し、エクスポートして再利用する方法をご紹介します。
Datastore からデータを読み込む準備
まず、注意点として、Datastore から BigQuery へ直接データをインポートすることはできません。
なので、一旦 Datastore から Cloud Storage へデータを移動します。
Datastore のデータを Cloud Storage に移動させるには、Datastore のバックアップ機能を利用します。
事前に Cloud Storage にバックアップを置くためのバケットを用意しておきましょう。
後ほど解説しますが、ここで作成するバケットは、東京リージョン(asia-northeast1)で作成することをおすすめします。
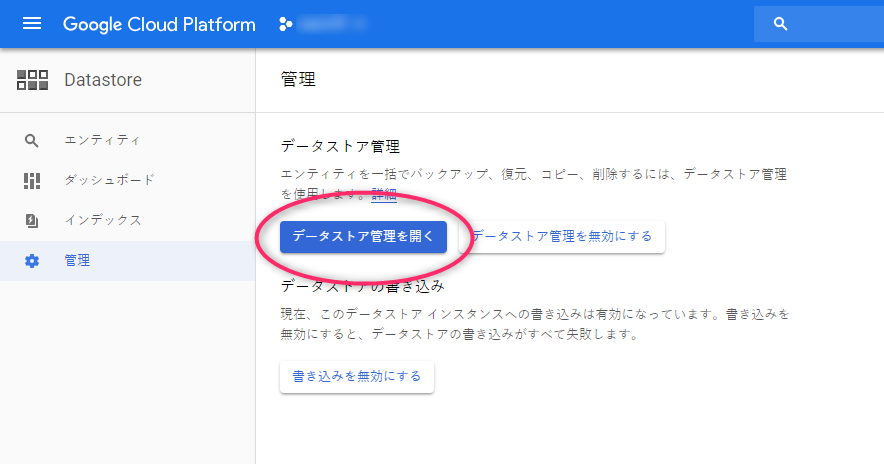
Datastore のメニューに「管理」という項目がありますので、そちらを選択します。
次に、「データストア管理を開く」というボタンがありますので、こちらをクリック。
リアルなデータをキャプチャしているので、モザイク多めですがご了承ください。
初回実行時のみ確認が入りますが、別ウィンドウが起動し、選択中のプロジェクト内のDatastore にある kind ごとのデータサイズの一覧が表示されます。
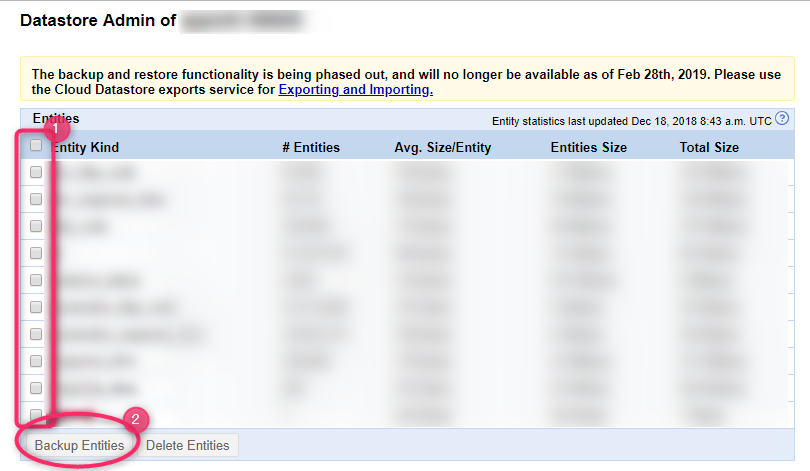
取り出すエンティティの Kind にチェックをつけ、「Backup Entities」をクリックすればバックアップが始まります。
書き出しはすぐには終わらないので、しばらく待ちます。

何回かリロードしてみて、上のような画面になれば完了しています。
BigQuery にデータを登録する
データの下準備が終わったら、BigQuery に読み込みます。
UI が新しくなったので、キャプチャ多めで進めたいと思います(こちらもモザイク多めですみません)。
BigQuery の画面に移動したら、左のメニューにあるリソースという項目の「データを追加」というリンクをクリックします。
「プロジェクトを固定」を選択し、Datastore のデータを保存した Cloud Storage のプロジェクトIDを選択。

下のように検索ボックスの下に指定したプロジェクトが表示されたら成功です。

次にプロジェクトにデータセットを作成します。
先程追加されたプロジェクトIDをクリックしてみます。
すると、右側のペインが切り替わり、クエリエディタになります。
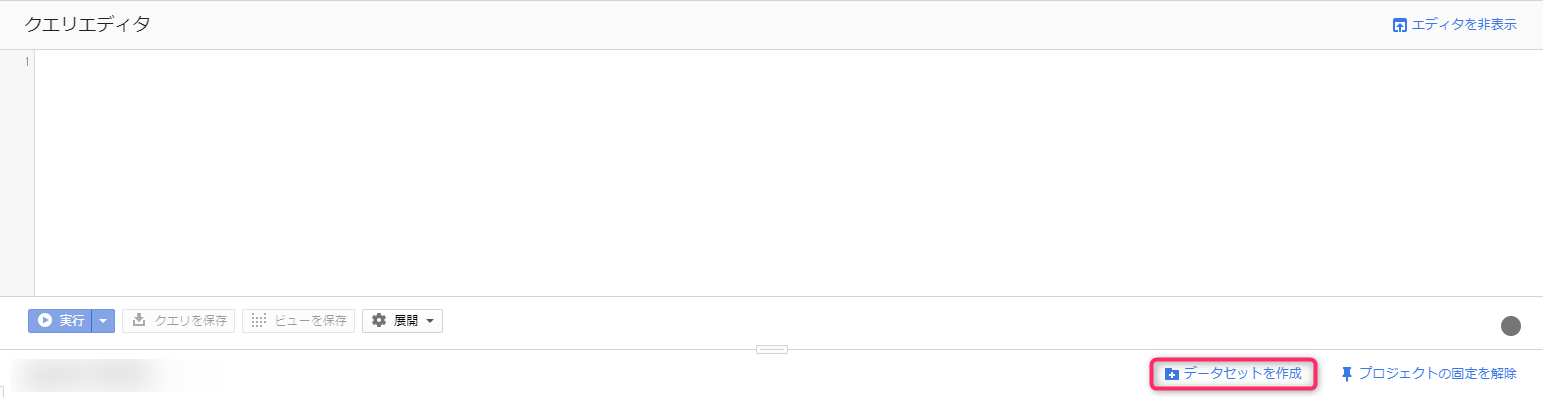
クエリエディタの下に、「データセットを作成」というリンクがあるので、それをクリックすると、データセットの作成画面が右からズズズ、と出てきます。
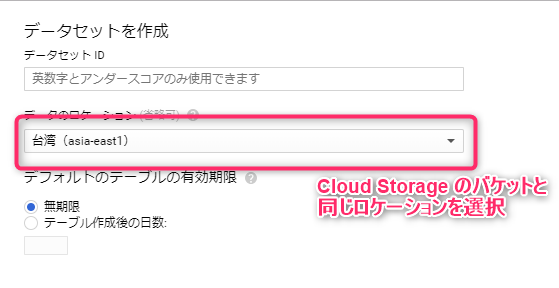
今から投入するデータを識別しやすいデータセットIDを入力し、データのロケーションを選択します。
ロケーションで重要なのは、一番最初に作成した Cloud Storage のバケットをおいたリージョンと合わせること。
Cloud Storage のバケットを東京リージョンに作成したら、asia-northeast1 を選択する、といった具合です。
BigQuery のデータをマルチリージョンで作成した場合は、Cloud Storage のバケットは選択したマルチリージョン内の地域にあるロケーションであればOKです。
記事を書いている時点では、BigQuery が選択できるマルチリージョンは、US と EU の2つで、ASIA は選択できません。
この記事通りに進めた場合、Cloud Storage のバケットを asia-northeast1 に作成したと思うので BigQuery のデータセットも asia-northeast1 に作成することになります。
データセットを作成したら、次にテーブルを作成します。
左のプロジェクトIDの下に先程作成したデータセットがぶら下がっているツリーが作成されているので、今度はデータセット名をクリックします。
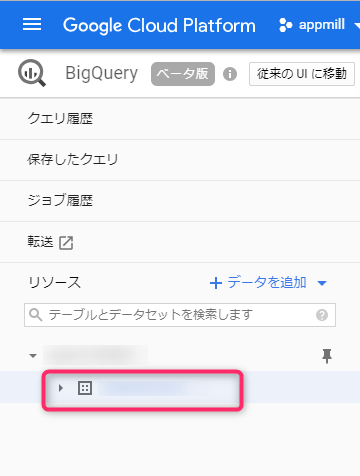
すると、右側のペインが切り替わり、「テーブルを作成」というリンクが表示されるので、そちらをクリック。
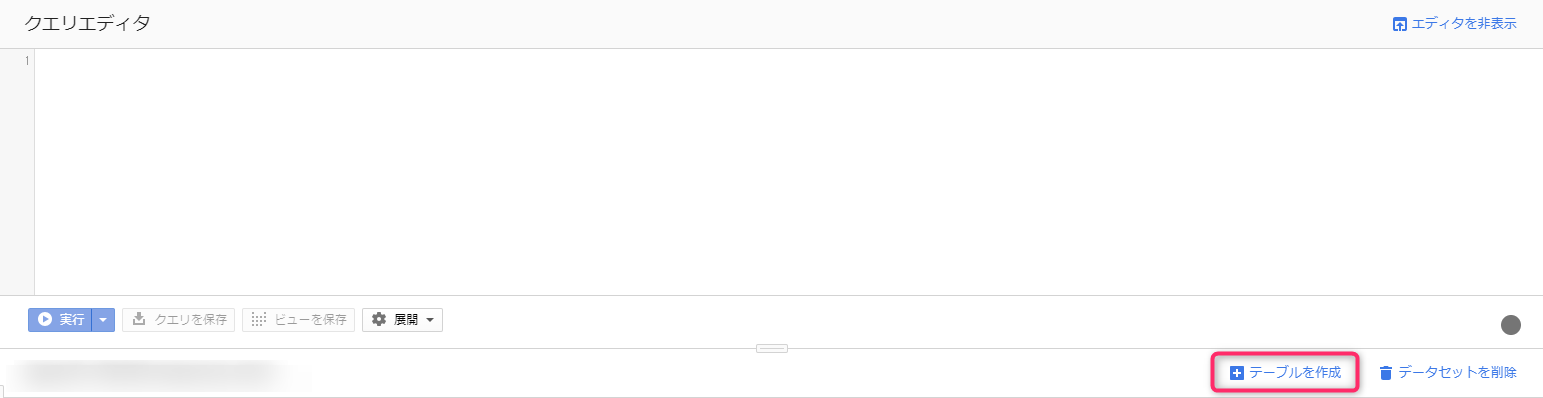
入力項目が多いですが、ひとつずつ解説します!
- テーブルの作成元
- データをどこから取得するかを選びます。アップロードならば、アップローダーが表示されます。今回は Cloud Storage を選択します。
- GCS バケットからファイルを選択
- Cloud Storage のバケット名から拡張子が「.[DatastoreのEntity Kind].backup_info」となっているファイルのパスを入力します。参照からディレクトリツリーを掘っていくこともできますが、.backup_info ファイルのファイル名が長すぎて見切れてしまうため、面倒ですがCloud Storage の画面からコピペしてくる方法をおすすめします。
- ファイル形式
- Cloud Datastore バックアップ を選びます。
- プロジェクト名
- この手順の場合、既に選択済みになっています。
- データセット名
- この手順の場合、既に選択済みになっています。
- テーブル名
- データセット内で識別しやすい名前をつけてあげてください。
他の項目は、特別な要件がない限り変更の必要はありません。
作成ボタンを押すと、データの読み込みジョブが作成され、ジョブ履歴に追加されます。
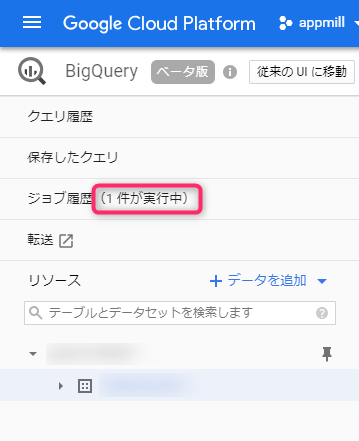
ジョブが完了し、テーブルにデータが格納されたら、クエリを実行する準備は整いました。
クエリを実行する
クエリを実行する前に、エディタにクエリを書いてみましょう。

上の画像では、存在しないデータセット、テーブルを指定しているためエラーになっています。
ただ、ここに書けるクエリは標準的な SQL のクエリが記述できるよう設計されています。
from の後のテーブル名には、データセット名とテーブル名をドットで繋いだ形で指定します。
存在するデータセット、テーブルを指定した場合は、以下のようになります。
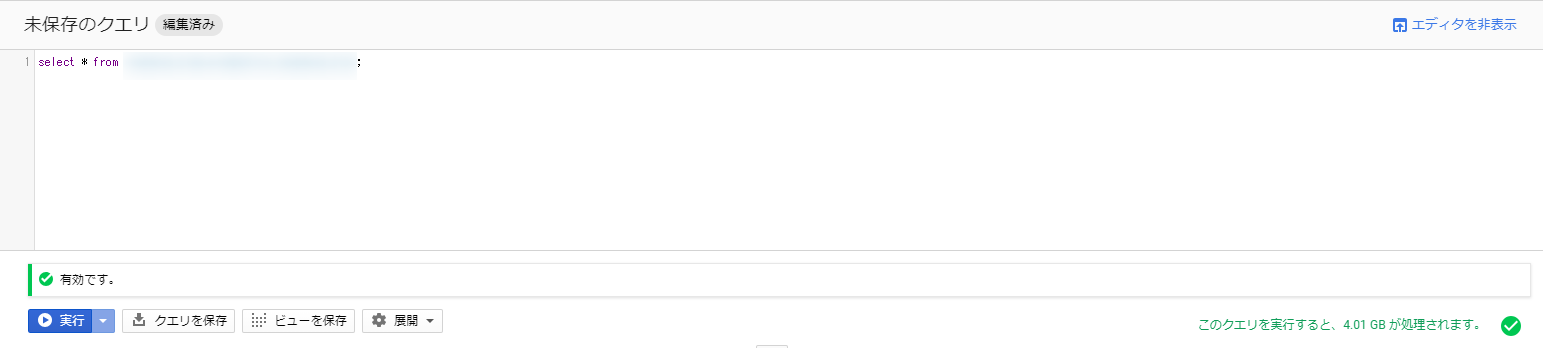
注目すべきところは右下の部分で、検索の結果出力されるデータサイズを表しています。
この部分が大きくなると、クエリの実行に掛かる料金が上がっていくことになります。
2018/12/19 現在、1TBあたり5ドルなので、あまり気にせず利用できるのではないでしょうか?
また、毎月1TB分の無料枠も設定されていて、試すには十分ではないかと思います。
今回試したデータでは、4.01GBのデータが処理される計算なので、約250回くらいは無料で実行できることになります。
また、同じクエリは24時間キャッシュされるので、再計算されず料金は掛かりません。
大盤振る舞いな無料枠をフルに使って、小さなデータでもどんどん使って慣れてみましょう!
現在の BigQuery では、SQL 2011 互換の標準 SQL が搭載されているので、MySQL や PostgreSQL しか使ったことがない方でもすんなり入っていけるようになりました。
とはいえ、MySQL ではできたのに、的なことはあるので、別の記事でご紹介したいと思います。
結果を書き出す
出来上がったデータをどこかに動かしたい場合は、結果をエクスポートすると便利です。
ここでは、実行結果を CSV にエクスポートし、Cloud Storage に置く方法をご紹介します。
クエリの実行結果を書き出す手段はいくつか用意されていますが、結果セットが小さなデータの場合、直接 CSV に書き出してダウンロードという方法が加工もしやすく手間がかかりません。
他にもプログラムで利用するなら JSON もいいですし、G Suite を活用されている会社などであれば、Google スプレッドシートという手もあります。
ただし、結果セットがが大きくなってきた場合、先頭の一部だけしかダウンロードできないため、一度 BigQuery テーブルにエクスポートする必要があります。

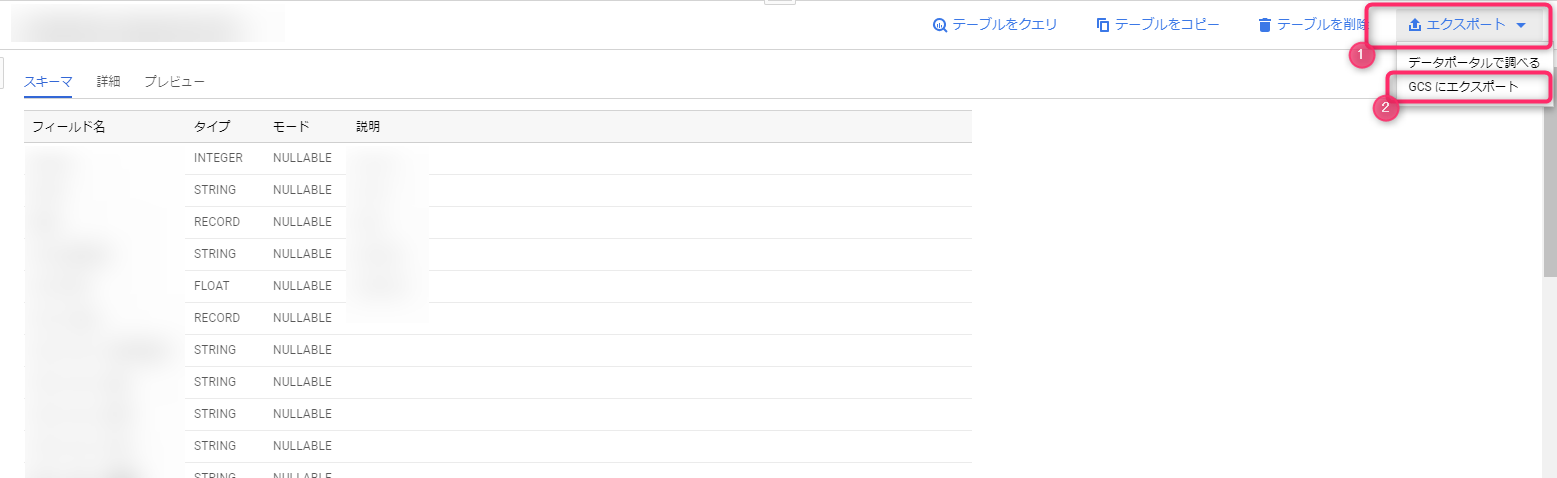
大きな結果セットを BigQuery テーブルに保存するには、クエリ結果のタイトルの横にある「結果を保存する」から BigQuery テーブル を選択します。
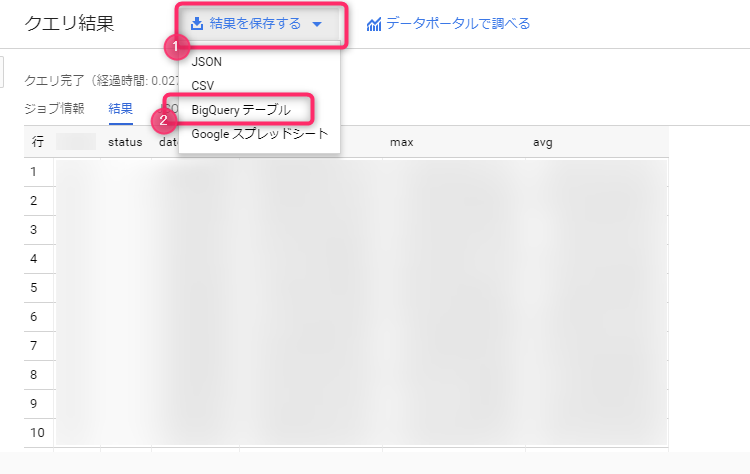
結果をテーブルとして保存するというモーダルが表示されるので、プロジェクト名、データセット名を選択し、書き出し先のテーブル名を入力すれば完了です。
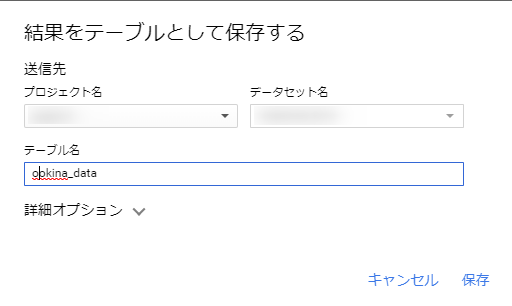
データサイズに応じて時間は掛かりますが、完了したら登録したデータセット内に新しくテーブルが追加されます。
このテーブルは、クエリ実行対象のテーブルと同じ扱いになるので、このテーブル自体をエクスポートする機能を使って、Cloud Storage にエクスポートしましょう。
BigQuery 内にテーブルを作成する場合は、10GB を超えた部分から料金が発生するので、検証などで利用される場合はご注意ください。
あとは、Cloud Storage のエクスポート先のバケット名から始まるフルパスを入力し、エクスポートする形式・圧縮の有無を選んだら、エクスポートが始まります。
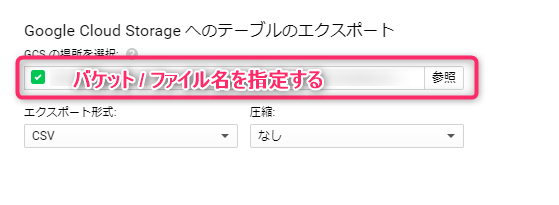
こちらもジョブとして管理され、ステータスが確認できます。

結果のデータサイズが小さかったので、このキャプチャを撮るのに苦労しましたね。
まとめ
今回は Datastore から BigQuery にデータを登録し、CSV 形式で Cloud Storage に保存する流れをまとめました。
ポイントとしては
- BigQuery はクエリが処理するデータ量によって値段が決まる従量課金制(定額もありますが、生半可な使い方では大赤字)
- BigQuery の標準 SQL は、微妙に MySQL に用意されているものと違いがある
- Cloud Storage を使えばデータのやり取りも簡単
- 個人的な感想ですが、BigQuery は使いやすいと思います
- Datastore から Cloud Storage にエクスポートするのに意外と時間がかかる
というところでしょうか。
クエリの実行時間もあっちゅーま、ストレスを感じない、いいサービスです!
人気なのもうなずけますね。
BigQuery からエクスポートする先は色々用意されていて、Google スプレッドシートは非エンジニアとのやり取りに適しているので、覚えておくといざという時に役立ちそうです。
以上です。
 00
00 この記事をかいた人
About the author


