ロードアベレージでサーバーの負荷を確認する方法とLinuxプロセスについて解説
2016.02.04
 1
1 
インフラエンジニアの伊藤です。
サーバー運用保守の悩みといえば、突然の負荷上昇です。
「とりあえずサービスが重い、けど原因がわからん!!」
ってことにならぬよう、まず確認することが多い「ロードアベレージ」がどういったものかをご紹介します。
ロードアベレージについて
負荷が高くてサイトやゲームが重い…ってときは、とりあえずtopコマンドを使うことになります。
topコマンドは、OSのそのタイミングの状態をリアルタイムに表示してくれます。
いっぱい情報があるので、どこを探っていけばいいかわからないかもしれません。
今回はロードアベレージについてですので、ロードアベレージを確認します。
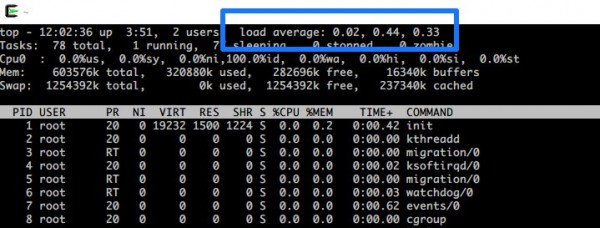
ロードアベレージ(LA)は、そのサーバーに対する「プロセスの待ち行列」を表し、一般的に1分、5分、15分といった期間の平均値として表示されます。
上の図で言うと、左から「1分前のLA」「5分前のLA」「15分前のLA」となっています。
色んなプロセスがCPUに対して処理してほしいってお願いをしているけど、サーバーが捌き切れないために、
そのプロセスが後ろに待ち行列を作っていく状態を表しています。
ロードアベレージの値が高ければ高いほど、そのサーバーの負荷は高い状態になります。
サーバーが一度に処理出来るプロセスの数は、「そのサーバーに乗っているCPUのコア数」になります。
マルチタスクで処理をこなすことが出来るので、例えば4コアのサーバーであれば、4つのプロセスの処理を一気にこなすことが出来ます。
Linuxプロセスについて
ロードアベレージについてざっくりご理解頂けたでしょうか。
ここで、Linuxのプロセスについて説明します。プロセスにも色んな状態があります。
| TASK_RUNNING | プロセスを実行可能な状態で、実行中or実行待ちの状態 |
|---|---|
| TASK_INTERRUPTIBLE | 割り込みが可能だけど、ユーザの入力待ちなどで、いつ復帰するかわからない状態 |
| TASK_UNINTERRUPTIBLE | サーバーの負荷が高く、割り込みができず待ち状態 |
| TASK_STOPPED | 中止された状態 |
| TASK_ZOMBIE | いわゆるゾンビプロセス |
参考:プロセス管理1 - プロセスディスクリプタ - Pridact情報共有用wiki
参考:Linuxのしくみを学ぶ - プロセス管理とスケジューリング
このうち、以下の3つに関しては負荷に関係ある状態ではありません。
- TASK_INTERRUPTIBLE:ユーザの入力待ちなどなので、いつ復帰するかわからないから待ち行列には入らない
- TASK_STOPPED:プロセスが止まっている
- TASK_ZONBIE:ゾンビ化している
つまり残った2つが待ち行列に入り、ロードアベレージの数値になり、「システムの負荷」ということになります。
「タスクが実行待ちの状態(TASK_RUNNING)」や「負荷が高く割り込み出来ない状態(TASK_UNINTERRUPTIBLE)」です。
- TASK_RUNNING
- TASK_UNINTERRUPTIBLE
他にLAが確認出来るコマンド
他にロードアベレージを確認出来るコマンドを2つ紹介します。
wコマンドは、他にどんなユーザがログインしているか確認することが出来ます。
[root@test ~]# w 12:49:13 up 4:38, 2 users, load average: 0.00, 0.00, 0.00 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT vagrant pts/0 10.0.2.2 11:43 0.00s 0.00s 0.00s sshd: vagrant [priv] vagrant pts/1 10.0.2.2 11:55 54:08 2.06s 0.00s sshd: vagrant [priv]
uptimeコマンドは、サーバがどれぐらいの時間動作し続けるか確認することが出来ます。
ここもロードアベレージが確認出来ます。
[root@test ~]# uptime 12:49:34 up 4:38, 2 users, load average: 0.00, 0.00, 0.00
まとめ
ということで、今回はロードアベレージについて説明しました!
- 負荷が高いときはロードアベレージを見てみる
- サーバーが処理しきれないプロセスの数がわかる
- ロードアベレージの数値が高いほど負荷が高い
- 一口に「プロセス」といってもいろんな状態がある
- ロードアベレージを見るコマンドは複数ある
こんなことを気にしないシステムを作ることが出来たらそれは最強なのですが、やっぱりサーバー運用していく中でこういった値を知っていくことってかなり大事なので、きちんと理解しましょう!
クラウドのプロに相談したい場合
弊社ビヨンドでは、創業以来、マルチクラウドインテグレーター・マネージドサービスプロバイダー(MSP)として培った技術力で、AWS や GCP・Azure・Oracle Cloud など、様々なクラウド / サーバーのプラットフォームを駆使した設計・構築・移行を行ってきました。
お客様が求めるシステムやアプリケーションの仕様・機能に応じて、お客様向けに最適化された、オーダーメイド型のクラウド / サーバー環境をご提供いたしますので、クラウドにご興味のある方はお気軽にお問い合わせください。
● クラウド / サーバー設計・構築
● クラウド / サーバー移行・マイグレーション
● クラウド / サーバー運用保守・監視(24時間365日)
11 この記事をかいた人
About the author


