
【大阪 / 横浜】インフラ / サーバーサイドエンジニア募集中!

【導入実績 500社以上】AWS 構築・運用保守・監視サービス

【CentOS 後継】AlmaLinux OS サーバー構築・移行サービス

【WordPress 専用】クラウドサーバー『ウェブスピード』

【格安】Webサイト セキュリティ自動診断「クイックスキャナー」
【予約システム開発】EDISONE カスタマイズ開発サービス

【100URLの登録が0円】Webサイト監視サービス『Appmill』

【200ヶ国以上に対応】グローバル eSIM「ビヨンドSIM」

【中国への旅行・出張・駐在なら】中国SIMサービス「チョコSIM」

【グローバル専用サービス】北米・中国でも、ビヨンドのMSP

【YouTube】ビヨンド公式チャンネル「びよまるチャンネル」
【RDB】Cloud Spanner の概要・特徴【グローバルデータベース】

技術営業部の大原です。
今回は、Google Cloudが提供するグローバルRDBサービス「Cloud Spanner」の概要・特徴を記載します。
Cloud Spanner の概要・特徴
Cloud Spanner は、フルマネージドの強力なリレーショナルデータベースサービスです。
グローバルスケールでのトランザクションの一貫性・スキーマ・SQL(ANSI 2011と拡張機能)・高可用性・ディザスタリカバリ(DR)のための自動同期レプリケーションを提供します。
リレーショナルデータベース構造の利点と、非リレーショナルの数千のノードに水平方向に拡張する、クラウド向けに構築された、エンタープライズグレードのグローバルに分散された、一貫性の高いデータベースサービスです。
Cloud Spanner を利用するケース
CloudSpannerを使用するケース・シナリオは以下の通りです。
● 強力な一貫性が必要なリレーショナルデータがある
● データのレプリケーションで高可用性が求められるケース
● データベースのマルチリージョン展開が必要なケース
● 高いスケーラビリティが必要なケース(小規模から始めて、必要に応じてスケールをすばやく増やすことができ、従来のリレーショナルOLTPシステムのスケール制限を超えることが可能です。)
Cloud Spanner のアーキテクチャ
Cloud Spannerはグローバルデータベースであり、リージョナル・マルチリージョナルの2種類の構成を提供します。
データを論理的に分割し、データの適切なレプリケーションとシャーディングを容易にするために、CloudSpannerはインスタンスとデータベースを使用します。
① インスタンス と データベース
インスタンスは、 そのインスタンスで作成された、Cloud Spannerのデータベースによって使用されるリソースの割り当てを指します。
インスタンスの作成は、インスタンス構成とノード数という2つの重要な選択肢で構成されます。
インスタンス構成は、そのインスタンス内のデータベースの地理的な配置とレプリケーションを定義します。
データベースは、インスタンス内のテーブルのコレクションです。
Cloud Spannerのデータベースには、データの読み取りと書き込みを可能にするテーブルとインデックスが保持されています。
インスタンスは複数のデータベースを持つことができます。
● リージョナルインスタンス
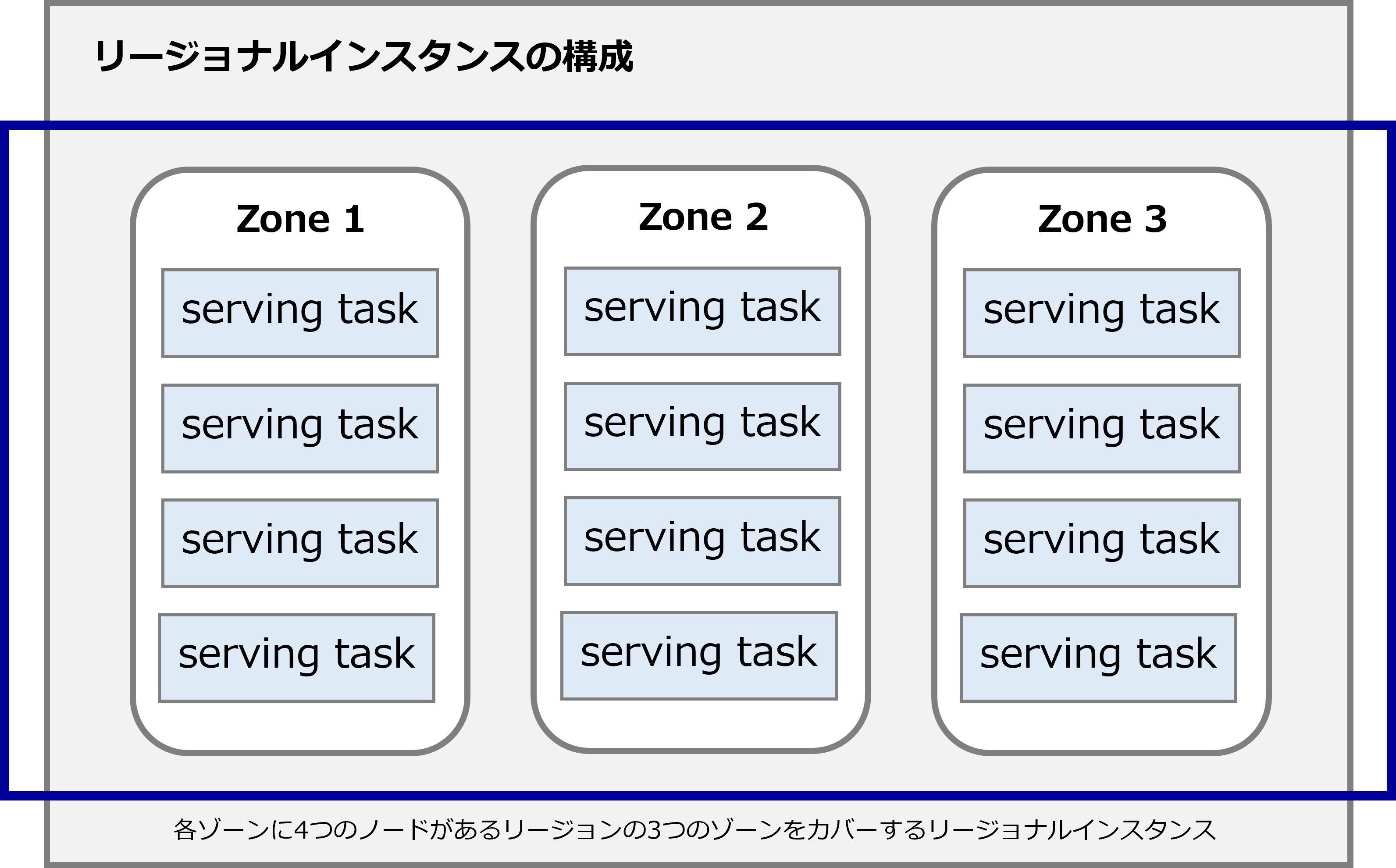
リージョナルインスタンスは、1つのGoogle Cloudのリージョンにまたがっています。
リージョナルインスタンスの構成では、Cloud Spannerは3つの読み取り/書き込みレプリカを維持し、それぞれがその地域の異なるGoogle Cloudのゾーン内にあります。
各読み取り/書き込みレプリカには、読み取り/書き込み・読み取り専用要求を処理できる運用データベースの完全なコピーが含まれています。
Cloud Spannerは、異なるゾーンでレプリカを使用するため、単一ゾーンの障害が発生した場合でも、データベースは引き続き使用できます。
● マルチリージョナルインスタンス
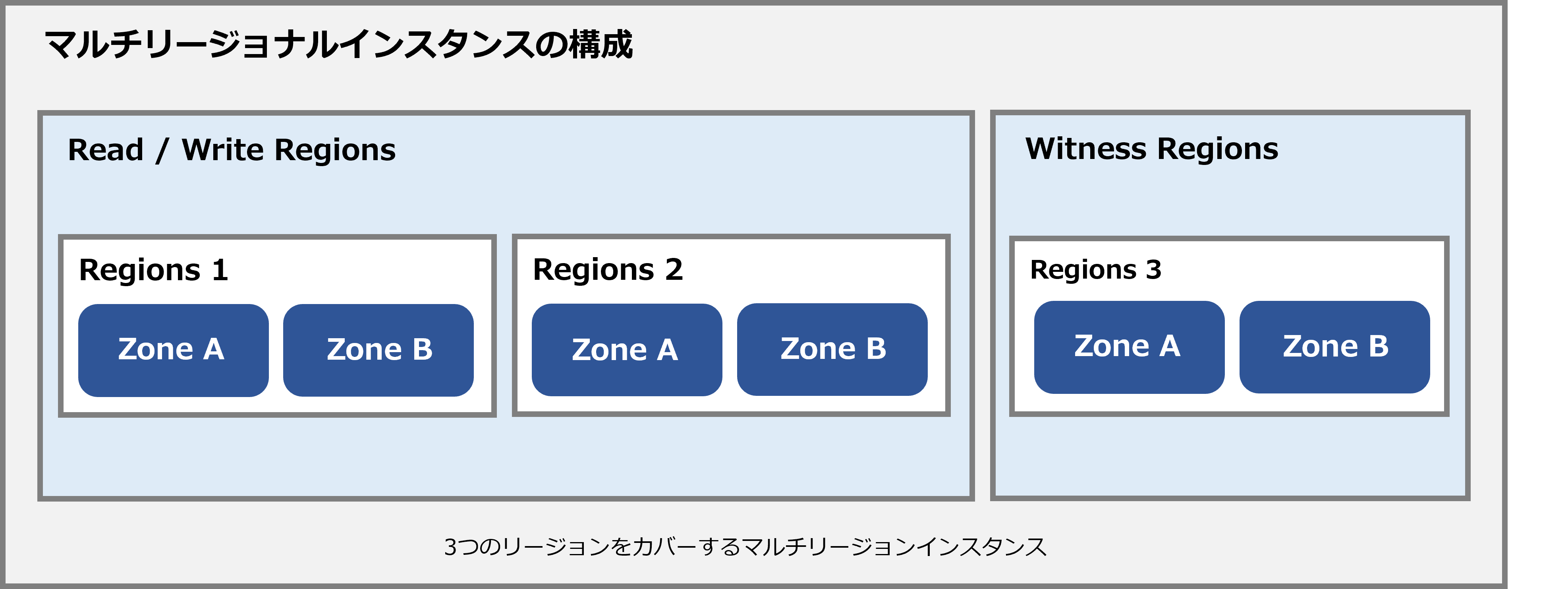
マルチリージョン構成では、インスタンス構成で定義されているように、データベースのデータを複数のゾーンだけでなく、複数のリージョンにまたがる複数のゾーンに複製できます。
これらの追加のレプリカを使用すると、構成内のリージョンに近い、またはリージョン内の複数の場所から、低レイテンシでデータを読み取ることができます。
書き込みレイテンシがわずかに増加する代わりに、アプリケーションがより多くの場所でより高速な読み取りを実現できるようになるため、マルチリージョンインスタンスは、地理的に複数の場所からデータを読み取る必要があるアプリケーションがある場合に非常に役立ちます。
各マルチリージョン構成には、読み取り/書き込み領域として指定された2つの領域が含まれ、各領域には2つの読み取り/書き込みレプリカが含まれます。これらの読み取り/書き込み領域の1つは、デフォルトのリーダー領域として指定されています。(データベースのリーダーレプリカが含まれていることを意味します)
※ マルチリージョン構成では、クォーラム(読み取り/書き込み)レプリカが複数のリージョンに分散され、トレードオフが伴うため、これらのレプリカが相互に通信して書き込みに投票すると、追加のネットワーク遅延が発生する可能性があります。(Cloud Spannerは少なくとも2つの異なるリージョンでコミットを永続化する必要があるため、コミットの待ち時間が長くなります)
② 高レベルのアーキテクチャ
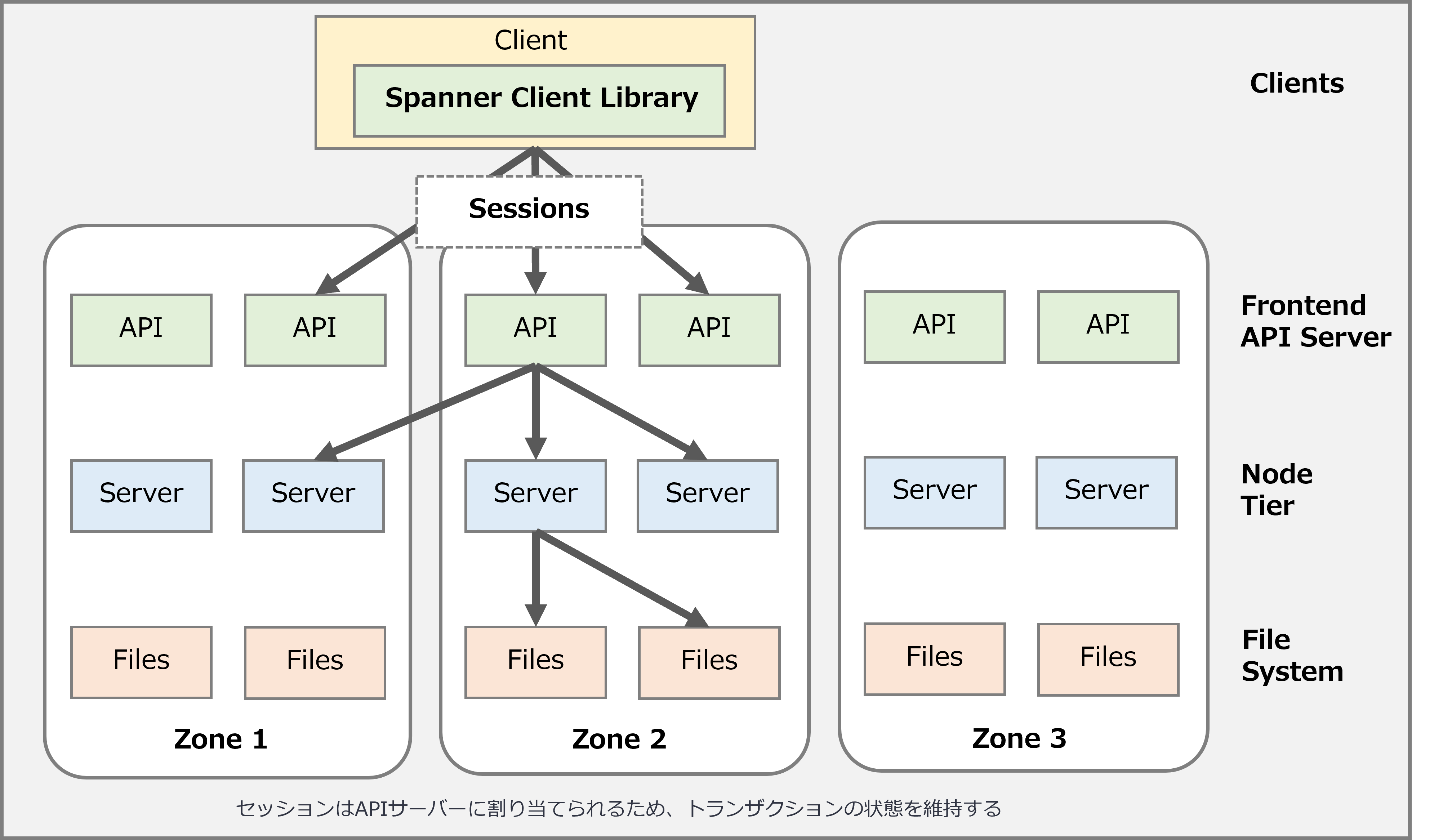 ザックリ言えば、Cloud Spannerの機能は、主にAPIサーバーによってサポートされています。
ザックリ言えば、Cloud Spannerの機能は、主にAPIサーバーによってサポートされています。
Cloud Spannerのクライアントライブラリの実行環境でセッションを使用して、Cloud Spannerと通信します。(各セッションは単一のデータベースに関連付けられており、一度に実行できるトランザクションは1つです)
セッションはAPIサーバーに割り当てられるため、トランザクションの状態を維持できます。
APIサーバーはゾーンまたはリージョンレベルではデプロイされませんが、リージョン間で共有でき、マルチリージョンを含めることができます。
APIリクエストに基づいて、APIサーバーはリクエストを完了するためにどのノードサーバーと通信するかを判断します。
ノードサーバーは、インスタンスに割り当てたノードであり、ほとんどの作業を実行します。
ノードサーバーは、読み取りおよび書き込み/コミットトランザクション要求を処理しますが、データを保存しません。
データは、他のストレージノードが提供するGoogleの基盤となる分散ファイルシステムに保存されます。
まとめ
Cloud Spanner を活用する所感として、ネットワークのレイテンシの少ない状態で、一貫したデータ処理を必要とする、グローバル展開している企業(各国にそれぞれデータを抱える企業)であれば、Cloud Spannerを導入してみる価値はありそうです。
 00
00 
【2024.6.30 CentOS サポート終了】CentOS サーバー移行ソリューション

【2025.6.30 Amazon Linux 2 サポート終了】Amazon Linux サーバー移行ソリューション

【大阪 / 横浜】インフラエンジニア・サーバーサイドエンジニア 積極採用中!
この記事をかいた人
About the author
