【スクレイピング入門】Pythonでサイト上のテーブルデータを取得する
2022.04.27
 9
9 
どうもはじめまして。
ちかごろ星のカービィディスカバリーにドはまり中のシステムソリューション部 かわいです。
既に暑いですが春ですね~。通勤時も初々しい新入社員らしき装いの方々をちょこちょこ見かけるようになりました(忘却の彼方)。
今回は、そんな新入社員の業務にもちょこっと役に立つ(かもしれない)、Pythonスクレイピングについての記事です。
スクレイピングとはなんぞや?
近年データ分析が注目されていますが、スクレイピングもその基礎となる技術で、主にWebサイト上から目的のデータを取得するための方法です。
もともとscrapeという言葉には「かき集める」という意味があり、そこから派生したようですね。
本記事ではPythonというプログラミング言語を使用し、ページ内のテーブル情報を自動的に取得します。

下準備
Pythonがインストールされていない場合、公式サイト:https://www.python.org/downloads/ から、
使用するOS向けのパッケージをダウンロード・インストールしてください。
完了後、今回使用するライブラリである「BeautifulSoup4」と「html.parser」をインストールします。
本記事ではWindows環境を想定しているので、検索窓、または[CTRL]+[R]キー押下→[cmd]と入力→コマンドプロンプトを開き、以下を実行します。下記のコマンドを実行するとインストールが始まります。
pip install bs4 html.parser
今回はMicrosoft社の以下ページから、Office 365で利用されているドメインやIPアドレス等の情報を自動で取得→csvファイルに書き出すまでをやってみたいと思います(手動で取ろうとすると結構めんどくさい)。
「Office 365 URL および IP アドレス範囲」>「Microsoft 365 Common および Office Online」
https://docs.microsoft.com/ja-jp/microsoft-365/enterprise/urls-and-ip-address-ranges?view=o365-worldwide
動作環境とコード全文
使用OS:Microsoft Windows 10 Pro
Pyhtonバージョン:3.10
from bs4 import BeautifulSoup
from html.parser import HTMLParser
import csv
from urllib.request import urlopen
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0"}
html = urlopen("https://docs.microsoft.com/ja-jp/microsoft-365/enterprise/urls-and-ip-address-ranges?view=o365-worldwide")
bsObj = BeautifulSoup(html, "html.parser")
table = bsObj.findAll("table")[4]
rows = table.findAll("tr")
with open(r"C:\Users\python\Desktop\python\2022\microsoft.csv", "w", encoding="cp932", newline="") as file:
writer = csv.writer(file)
for row in rows:
csvRow = []
for cell in row.findAll(["td", "th"]):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
コード解説
from bs4 import BeautifulSoup from html.parser import HTMLParser import csv from urllib.request import urlopen
→ 各ライブラリをインポートさせます。
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0"}
html = urlopen("https://docs.microsoft.com/ja-jp/microsoft-365/enterprise/urls-and-ip-address-ranges?view=o365-worldwide")
bsObj = BeautifulSoup(html, "html.parser")
→ ユーザエージェント情報を付与します(今回はFirefoxとします)。
urlopenで開きたいページを指定し、BeautifulSoupで読み取らせるためにここで宣言します。
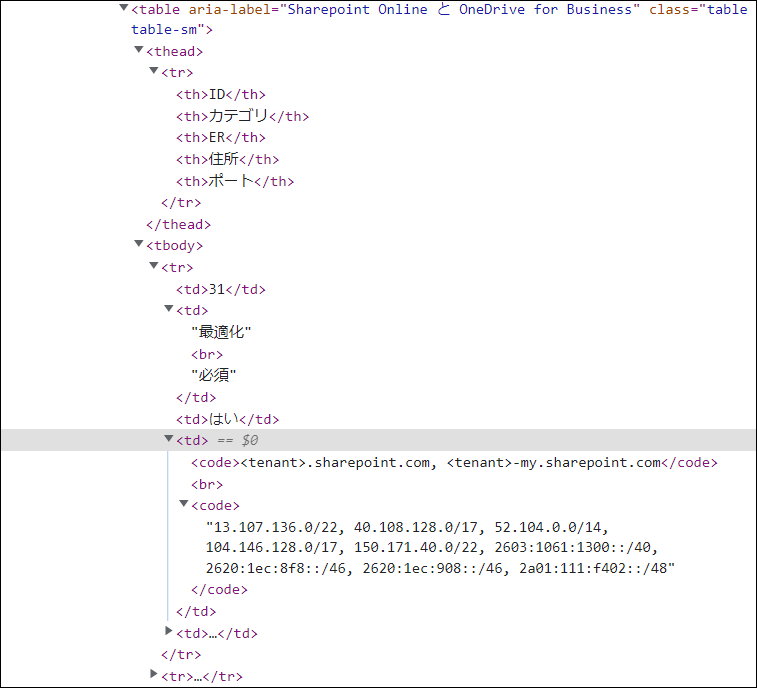
table = bsObj.findAll("table")[4]
rows = table.findAll("tr")
→ 今回のHTMLの構造(各ブラウザのWebデベロッパツールを使用します)から、4つ目のテーブルとして[4]を指定します。また、findAllで"tr"タグを探します。
with open(r"C:\Users\python\Desktop\python\2022\microsoft.csv", "w", encoding="cp932", newline="") as file: writer = csv.writer(file) for row in rows: csvRow = [] for cell in row.findAll(["td", "th"]): csvRow.append(cell.get_text()) writer.writerow(csvRow)
→ 任意のパスとファイル名で文字コード等を指定します(ファイルが存在しない場合、指定したパスにファイルが作成されます)。
「w」で書き込み、「newline=""」で取得した情報を一列毎に改行して書き出しが可能です。
前述列で指定した rows(trタグ)内からtd と th を探し、ループ処理でその列の値を取得→csvファイルに書き込みます。
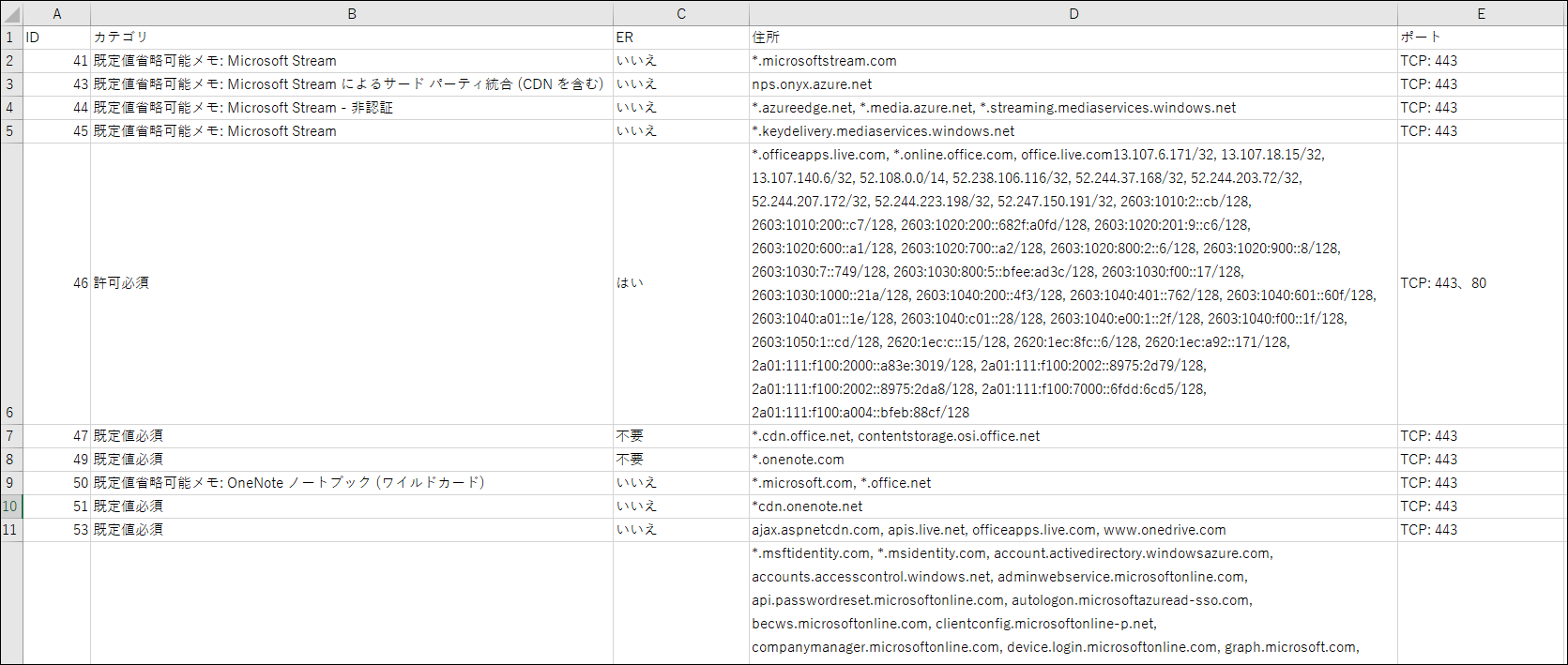
出力結果
こんなん出ました。今回は数件の情報だけですが、取得する情報が多ければ多いほど効率的になりますね。
また機会があれば、誰かの役に立つような記事を書いていきたいと思います~。ではまた
99 この記事をかいた人
About the author


