Pythonを使ってcsvから特定期間のデータを集計する【pandas】

こんにちは。
夢はつよつよ中身はよわよわ システムソリューション部のかわです。
過ごしやすい季節になりましたね。
ということで今回は主にPythonデータ分析の基本ライブラリ「pandas(パンダス)」を使って、
csvファイルから大量のデータを集計したいと思います。
環境
使用OS:Microsoft Windows 10 Pro
Pythonバージョン: 3.10.4
全体像
import pandas as pd
from datetime import datetime as dt
import collections
import itertools
df = pd.read_csv('<ファイル名>.csv',
usecols=['datetime', 'person_in_charge'],
encoding='cp932'
)
df_date = df.set_index('datetime')
#エラーチェック用
def check(x):
#print(x)
pd.to_datetime(x)
df_date.index.map(check)
df_date.index=pd.to_datetime(df_date.index,format='%Y%m%d %H:%M')
df_date.sort_index(inplace=True)
df_date['count'] = 1
df_multi = df_date.set_index([df_date.index.year, df_date.index.month, df_date.index.weekday,
df_date.index.hour, df_date.index])
df_multi.index.names = ['year', 'month', 'weekday', 'hour', 'date']
df_date['person_in_charge'] = df_date['person_in_charge'].str.split(',')
all_tag_list = list(itertools.chain.from_iterable(df_date['person_in_charge']))
c = collections.Counter(itertools.chain.from_iterable(df_date['person_in_charge']))
tags = pd.Series(c)
df_tag_list = []
top_tag_list = tags.sort_values(ascending=False).index[:11].tolist()
for t in top_tag_list:
df_tag = df_date[df_date['person_in_charge'].apply(lambda x: t in x)]
df_tag_list.append(df_tag[['count']].resample('1M').sum())
df_tags = pd.concat(df_tag_list, axis=1)
df_tags.columns = top_tag_list
df_tags.to_csv('result.csv', encoding='cp932')
print("done")
目的と下準備
生データとなるcsvファイルには、問合せを受けつけた日付(yyyy/mm/dd形式)と
それらを受けた担当者名を出力した内容が大量に記録されているものと想定します。
前処理として、日付のカラム名を「datetime」、担当者名を「person_in_charge」としています。
ライブラリとしてpandasを使うので、pipからインストールが必要です。
(Anaconda等他環境の場合はリンク先を参照)
部分解説
▼ ファイルをpandasで読み込みます。csvファイルは、コードファイルと同じフォルダに配置してます
df = pd.read_csv('<ファイル名>.csv',
usecols=['datetime', 'person_in_charge'],
encoding='cp932'
)
▼ df.set_index で「datetime」カラムをインデックスに割り当て。
※後半の箇所は空欄セルがないかのチェック用なので省いてもok
df_date = df.set_index('datetime')
def check(x):
pd.to_datetime(x)
df_date.index.map(check)
▼ データ型をdatetime用フォーマットに変換&ソート
df_date.index=pd.to_datetime(df_date.index,format='%Y%m%d %H:%M') df_date.sort_index(inplace=True) #resamplingのためにカウント列を追加 df_date['count'] = 1
▼ 日や時間ごとにグルーピングとかカウントとか
df_multi = df_date.set_index([df_date.index.year, df_date.index.month, df_date.index.weekday,
df_date.index.hour, df_date.index])
df_multi.index.names = ['year', 'month', 'weekday', 'hour', 'date']
df_date['person_in_charge'] = df_date['person_in_charge'].str.split(',')
all_tag_list = list(itertools.chain.from_iterable(df_date['person_in_charge']))
#iiterateをcollectionに渡す。各タグの出現回数をカウント
c = collections.Counter(itertools.chain.from_iterable(df_date['person_in_charge']))
#seriesに変換
tags = pd.Series(c)
▼ タグをDataFrameに格納
df_tag_list = [] top_tag_list = tags.sort_values(ascending=False).index[:11].tolist()
▼ ここが肝「df_tag_list.append(df_tag[['count']].resample('1M').sum())」の「'1M'」部分を、
例えば「'2W'」にすれば2週間ごと、「'7D'」にすれば7日ごとの集計が可能。
for t in top_tag_list:
df_tag = df_date[df_date['person_in_charge'].apply(lambda x: t in x)]
df_tag_list.append(df_tag[['count']].resample('1M').sum())
df_tags = pd.concat(df_tag_list, axis=1)
df_tags.columns = top_tag_list
▼ 集計データを新規ファイルに出力
df_tags.to_csv('result.csv', encoding='cp932')
#終わったら「done」を出力
print("done")
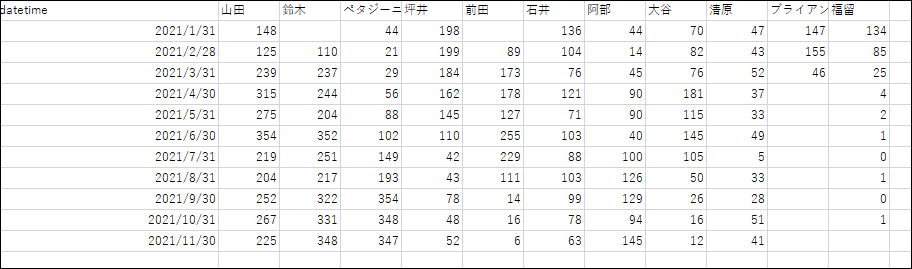
出力結果
こんなん出ました
月ごとの担当者別集計データの出来上がり。必要に応じて週別や日別に集計して、
うまーく装飾すれば会議でもデータとして使ったりできそうですね!
ではまた!
 77
77 この記事をかいた人
About the author


