【コンテナ】Datadog による Kubernetes のインフラ監視【モニタリング】

技術営業部の大原です。
今回は Datadog の監視ツールを使った、Kubernetes 環境のインフラ監視に関する記事です。
「なぜ Kubernetes のような動的・可変的なインフラ環境に 統合監視ツールが必要なのか?」という観点から、特徴やポイントについて記載します。
(2022年3月時点の情報です)
Kubernetes 環境のインフラ監視の課題
インフラの拡張性と耐障害性を向上させるために、Kubernetes のようなオーケストレーションシステムの導入が進んでいますが、従来のような仮想マシンや物理マシンなど、長期間使用される静的なホストのみを監視するケースとは違い、Kubernetes のように、動的で複雑に組み込まれた環境では、Datadog のような統合監視ツールを使用した、ホスト・コンテナ・アプリケーション・Kubernetes 全体をリアルタイムに可視化できるようなモニタリング・監視が必要とされます。
● 監視すべきコンポーネントの増加
・従来のホスト中心のインフラストラクチャでは、監視すべき主なレイヤーは「アプリケーション」「アプリケーションを実行しているホスト」の2つが中心となります。オーケストレーション環境では、抽象化レイヤーが 新しく追加されており、インフラストラクチャを包括的に追跡するためには、コンテナや Kubernetes 自体を監視する必要があります。
● 分散化されたアプリケーションは 常に移動する
・Kubernetes はホスト間で Pod を常に移動し、需要に合わせてスケールアップおよびスケールダウンします。アプリケーション、コンテンツを正しく把握するためには、全ての Pod と、Pod 内で実行されているアプリケーションを監視する必要があります。しかし、Kubernetes はワークロードを自動的にスケジューリングしているため、実際にこれらの Pod がどこで実行されているか継続的にチェックすることは困難です。
● 継続的な可視化にタグとラベルは不可欠
・一般的な Kubernetes クラスタには 多くの動的 / 可変な要素があるため、タグとラベルは Pod と Pod 内のアプリケーションを識別するための 唯一の信頼できる方法です。ラベルやタグがなければ、変化し続ける Kubernetes インフラストラクチャのパフォーマンスデータを集計または解釈することはほぼ不可能です。
あらゆる規模のKubernetesプラットフォーム環境を監視

Kubernetes クラスタは、様々なプラットフォーム上で動作します。全ての主要なクラウドプロバイダに対応する、Datadog の 400 以上の構築済のインテグレーションを使用すると、バックグラウンドで使用しているプラットフォームに関わらず、コンテナ化された全てのアプリケーションがオンラインになったときに、そのヘルスとパフォーマンスを監視できます。
また、完全にマネージドのプラットフォームを選択する組織もあれば、Rancher や OpenShift、または Anthos を使用してホスティングするケースであっても、クラスタのステータスや下位レベルのリソースメトリクスから分散トレースやログまで、Datadog は Kubernetes インフラストラクチャとアプリケーションの、全てのデータを単一の統合型のプラットフォームに集約します。
Datadog であれば、Kubernetes・Docker・クラウドプロバイダーのタグによって自動的にデータを拡充し、発生したイベントを簡単に調査できるため、実行するノードが数十台でも数千台でも、Datadog は最小限のセットアップで Kubernetes クラスタを詳細に可視化することで、安全にコンテナ環境の構築・デプロイ・拡張を可能とします。
全ての Kubernetes データを一箇所に集約
Datadog では、Kubernetes 環境の全てのレイヤーで何が起こっているかを把握します。DaemonSet または Datadog Operator を使用すれば、クラスタ内の全てのノードに Datadog Agent を簡単にデプロイできます。Datadog の Kubernetes インテグレーションを使用すると、以下のようなことが可能になります。
◆ コントロールプレーンを健全に維持する
● コントロールプレーンの各パーツの追跡
・スケジューラ / API サーバー / コントローラマネージャーなど、コントロールプレーンの全てのコンポーネントのヘルスとパフォーマンスを監視します。コントロールプレーンを健全に維持できれば、ワークロードを適切にスケジュールおよびオーケストレーションすることができ、クラスタをスムーズに稼働できます。
● 自動アラートの設定
・200 以外の HTTP 応答コードの異常な急増など、コントロールプレーンのクリティカルな問題が顧客に影響を与える前に検出して解決します。
◆ Kubernetes の問題のトラブルシューティング
● Kubernetes 環境のフルスタックを可視化
・Kubernetes ワークロードとアプリケーションのメトリクス / ログ / 分散トレース間をシームレスに移動でき、パフォーマンスに関する問題を迅速にトラブルシューティングできます。カスタマイズ可能で簡単にすぐ使用できる ダッシュボードで、データをリアルタイムで可視化できます。
● Kubernetes 監査ログの分析
・ユーザーやサービスから、クラスタへのアクセスに影響する可能性のある、API認証の問題をトラブルシューティングします。
● タグを使用したドリルダウン
・Datadog は、Kubernetes / Docker / クラウドプロバイダからタグを自動的に収集するため、データを簡単にソート・フィルタリング・集計できます。リージョン・コンテナイメージ・Pod 名、または 他のカテゴリーで問題の範囲をすばやく絞り込むことができ、平均解決時間を短縮します。
◆ あらゆる場所のサービスの状況を自動検出
● オーケストレーションされたサービスを動的に監視
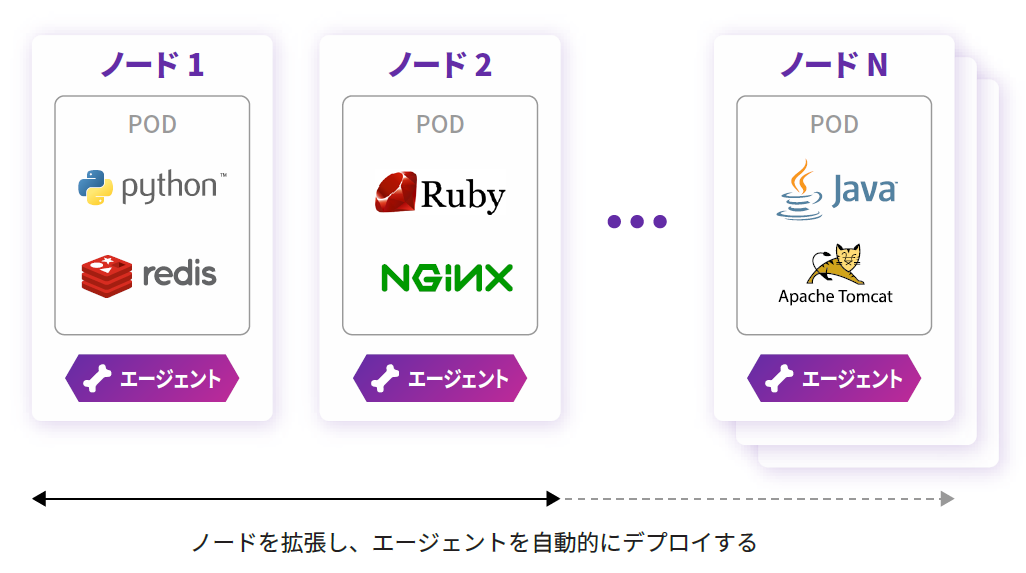
・Datadog は、クラスタ内の変更を検出し、ユーザーがセットアップしなくても、さまざまなクラスタコンポーネント(Kubernetes API サーバーなど)や一般的なインフラストラクチャテクノロジ(Apache Tomcat や Redis など)からデータ収集を自動的に開始します。また、Agent チェック用のカスタムコンフィグレーションテンプレートを定義し、各チェックで監視すべきコンテナを指定できます。
◆ 任意のメトリクスを使用したワークロードの自動拡張
● 大規模な環境でも高品質なカスタマーエクスペリエンスを実現
・Datadog を Kubernetes の Horizontal Pod Autoscaler と一緒に使用すると、予期せぬトラフィックが発生した場合でもアプリケーションの可用性を維持できます。インテグレーション固有のメトリクス(MySQL のクエリスループットなど)からカスタムのビジネスメトリクスまで、Datadog で監視しているあらゆるメトリクスに基づいてワークロードを拡張できます。(例:日々のページビューなど)
まとめ
Kubernetes のような動的・可変的なインフラ環境には、従来のような監視ツールを用いた運用では難しい場合があるため、Datadogのような統合監視ツールを導入し、運用パフォーマンスを高めていくのがオススメです。
また、今回は Kubernetes のコンテナ環境の概念・観点からの記事でしたが、AWSなどのクラウド環境を使用した、Amazon EC2 などのインスタンスの Auto Scaling 機能・環境 の運用にも、一部は当てはまる内容ですので、本記事を参考にしていただけると嬉しいです。
 33
33 この記事をかいた人
About the author

