非常适合在新年假期学习!将数据存储数据加载并分析到 GCP BigQuery 中

大家好,
我是开发团队野生队的成员 Mandai。
我想分析来自 Appmill 的监控数据,但数据量越来越大,难以存储在数据库中。
说到 GCP,就只能这样了。
没错,这就是 BigQuery 的用武之地。
这次,我们将向您展示如何将 GCP 上的 Datastore 数据导入 BigQuery,对其运行查询,并将其导出以供重用。
准备从数据存储加载数据
首先请注意,您无法直接从 Datastore 导入数据到 BigQuery。
因此,我们首先将数据从数据存储迁移到云存储。
要将 Datastore 数据迁移到 Cloud Storage,请使用 Datastore 的备份功能。
请预先在 Cloud Storage 中创建一个存储桶来存储备份。
稍后会详细说明,我们建议在东京区域(asia-northeast1)创建存储桶。
数据存储菜单中有一个名为“管理”的选项,请选择它。
接下来,您会看到一个名为“打开数据存储管理”的按钮。点击它。
请注意,由于这是真实数据的采集,因此画面会呈现很多马赛克效果。
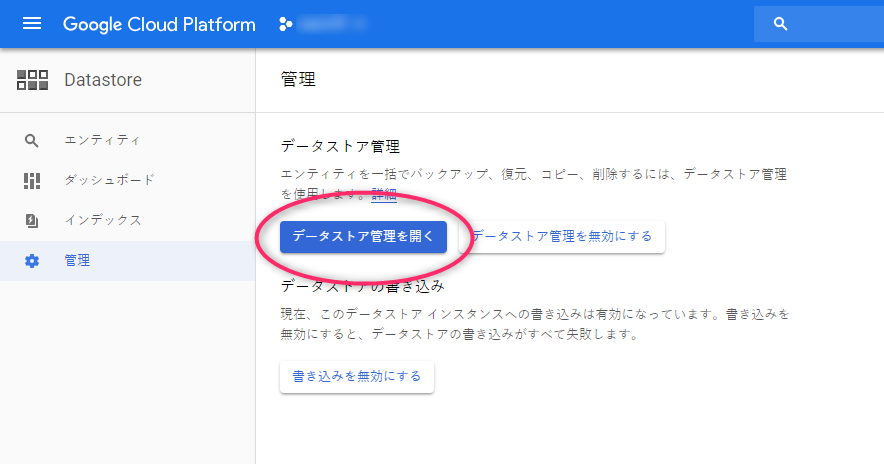
只有在第一次运行程序时才会要求您确认,但会打开一个单独的窗口,显示所选项目中数据存储中每种类型的数据大小列表。
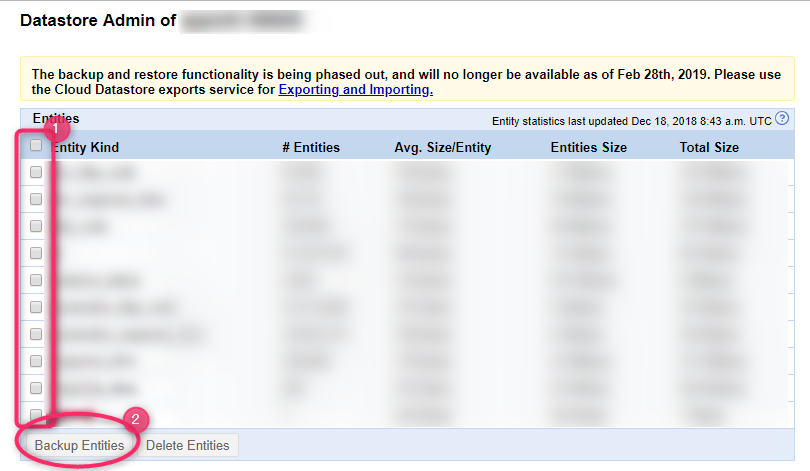
选中要提取的实体类型,然后点击“备份实体”开始备份。
导出过程不会立即完成,请稍候。

尝试重新加载几次,一旦看到上面的屏幕,就表示加载完成。
在 BigQuery 中注册数据
数据准备完成后,我们会将其加载到 BigQuery 中。
由于用户界面已更新,我会附上很多屏幕截图(抱歉背景有些模糊)。
进入 BigQuery 界面后,点击左侧菜单“资源”部分下的“添加数据”链接。
选择“指定项目”,然后选择您保存 Datastore 数据的 Cloud Storage 项目 ID。

如果指定的项目出现在搜索框下方(如下图所示),则表示您已成功。

接下来,在项目中创建一个数据集。
点击您刚刚添加的项目 ID。
右侧窗格将切换到查询编辑器。
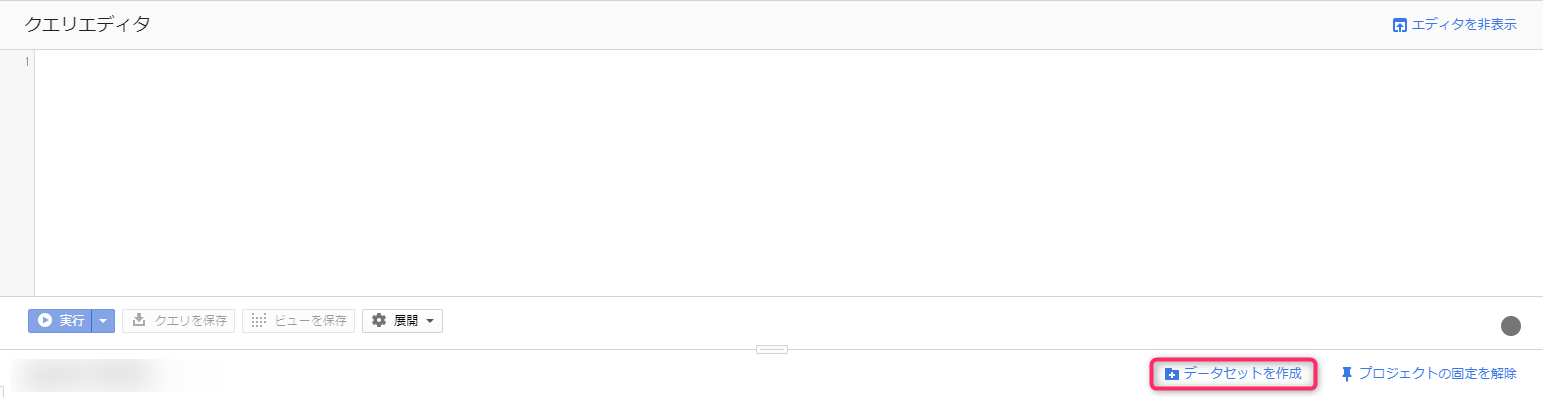
在查询编辑器下方,有一个名为“创建数据集”的链接。点击该链接,数据集创建界面将从右侧弹出。
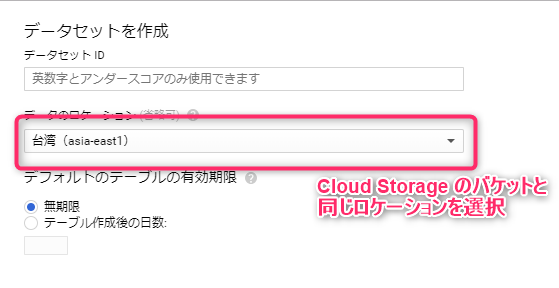
输入数据集 ID,以便轻松识别即将输入的数据,并选择数据位置。
位置信息必须与您最初创建的 Cloud Storage 存储桶所在的区域一致。
如果您在东京区域创建 Cloud Storage 存储桶,则应选择 asia-northeast1。
如果您在多区域环境中创建了 BigQuery 数据,则 Cloud Storage 存储桶可以位于所选多区域环境内的任何位置。
截至撰写本文时,BigQuery 仅支持两个多区域选项:美国和欧盟;亚洲区域暂不可用。
如果你按照本文操作,你将在 asia-northeast1 中创建 Cloud Storage 存储桶,因此你也将在 asia-northeast1 中创建 BigQuery 数据集。
创建数据集之后,就可以创建表格了。
将会创建一个树状图,其中你刚刚创建的数据集悬挂在左侧的项目 ID 下方,现在点击数据集名称。
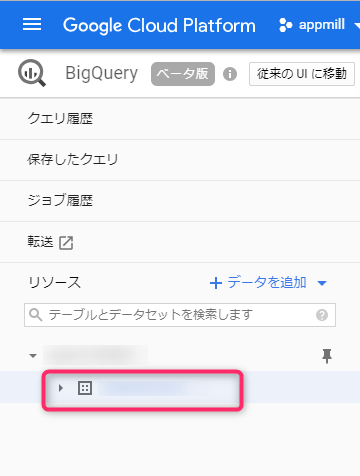
右侧窗格随后会切换,并出现一个名为“创建表格”的链接,点击它即可。
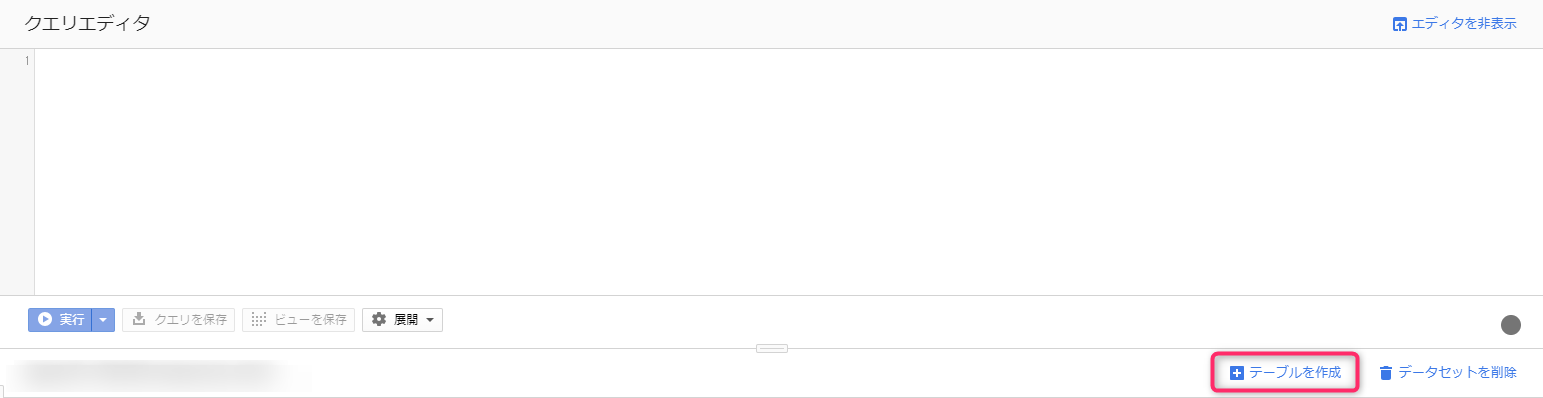
输入字段很多,我们会逐一解释!
- 表格由
- 选择数据来源。如果选择上传,则会显示上传工具。在本例中,选择云存储。
- 从 GCS 存储桶中选择文件
- 输入云存储桶名称中扩展名为“.[数据存储实体类型].backup_info”的文件路径。您也可以浏览目录树,但由于 .backup_info 文件的文件名过长会被截断,因此我们建议您从云存储屏幕复制并粘贴该文件,尽管这样做比较麻烦。
- 文件格式
- 选择云数据存储备份。
- 项目名称
- 此步骤已选中。
- 数据集名称
- 此步骤已选中。
- 表名
- 给它起一个便于在数据集中识别的名字。
除非有特殊要求,其他项目无需更改。
按下“创建”按钮后,将创建一个数据加载作业并将其添加到作业历史记录中。
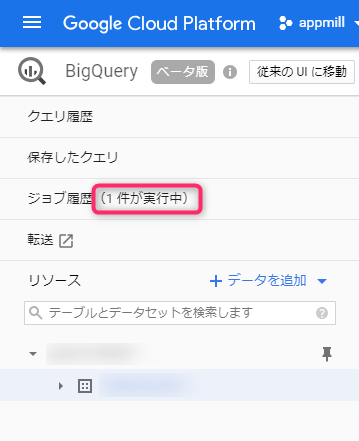
作业完成后,表格中就会填充数据,这时就可以运行查询了。
执行查询
在执行查询之前,让我们先在编辑器中编写查询语句。

上图中出现错误是因为指定了不存在的数据集和表。
但是,此处可编写的查询语句旨在允许编写标准的 SQL 查询。
在“from”之后的表名中,请指定数据集名称和表名称,并用点号连接。
如果指定一个已存在的数据集和表,则格式如下:
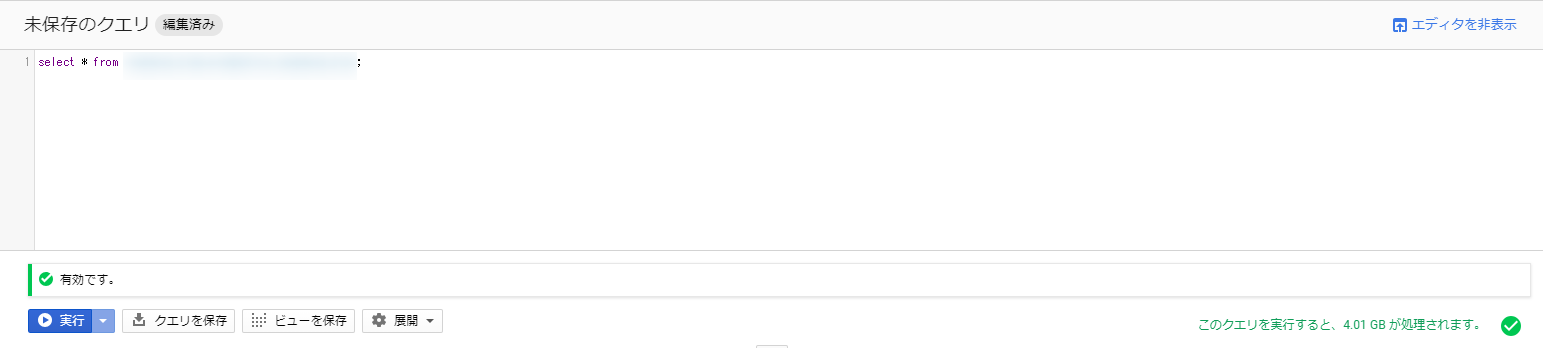
需要关注的是右下角部分,它显示了搜索结果输出的数据量。
这部分数值越大,执行查询的成本就越高。
截至2018年12月19日,价格为每TB 5美元,所以您可以放心使用。
此外,每月还有1TB的免费流量,我认为这足够您试用了。
本次测试使用了 4.01GB 的数据,这意味着您可以免费运行该查询约 250 次。
此外,该查询会被缓存 24 小时,因此不会重新计算,也不会产生任何费用。
充分利用慷慨的免费流量,并养成即使使用少量数据也要坚持使用的习惯!
BigQuery 现在自带与 SQL Server 2011 兼容的标准 SQL,因此即使是只使用过 MySQL 或 PostgreSQL 的用户也能轻松上手。
不过,MySQL 仍然有一些强大的功能,我将在另一篇文章中介绍。
导出结果
如果要将结果数据转移到其他地方,导出结果会很方便。
在这里我们将向您展示如何将执行结果导出为 CSV 并将其存储在云存储中。
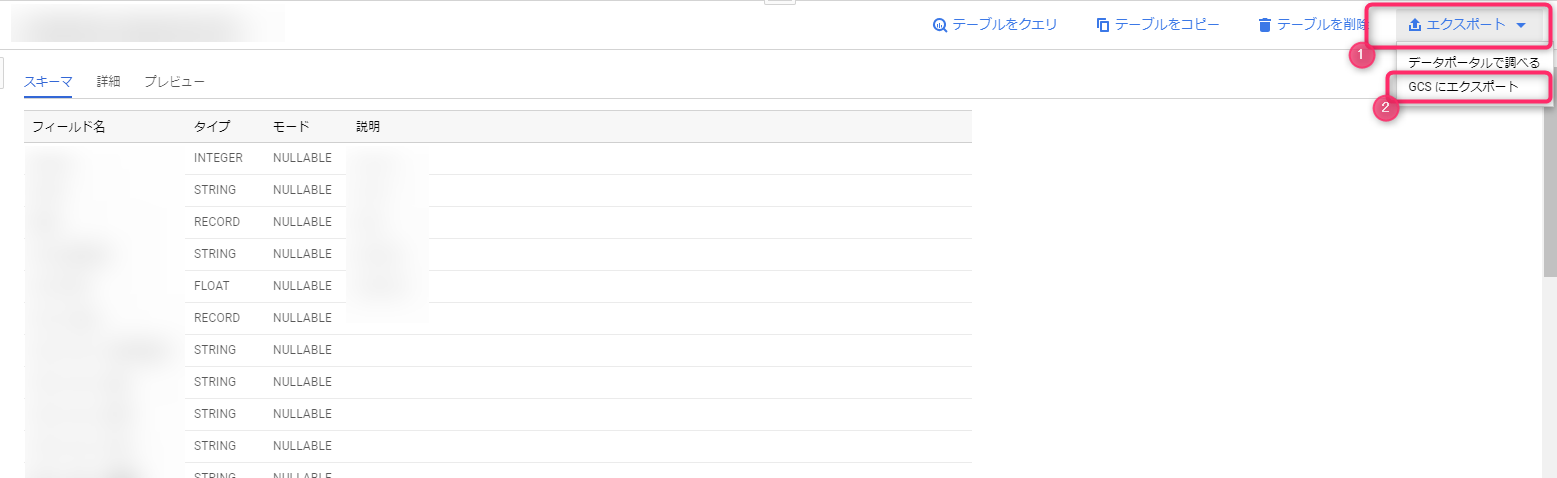
导出查询结果的方法有很多种,但如果结果集较小,直接导出为 CSV 文件并下载既简单又省时。
其他选项包括:如果您计划在程序中使用,可以选择 JSON 格式;如果您的公司使用 G Suite,可以选择 Google 表格。
但是,如果结果集很大,则需要先将其导出到 BigQuery 表中,因为您只能下载第一部分。

要将大型结果集保存到 BigQuery 表中,请从查询结果标题旁边的“保存结果”中选择 BigQuery 表。
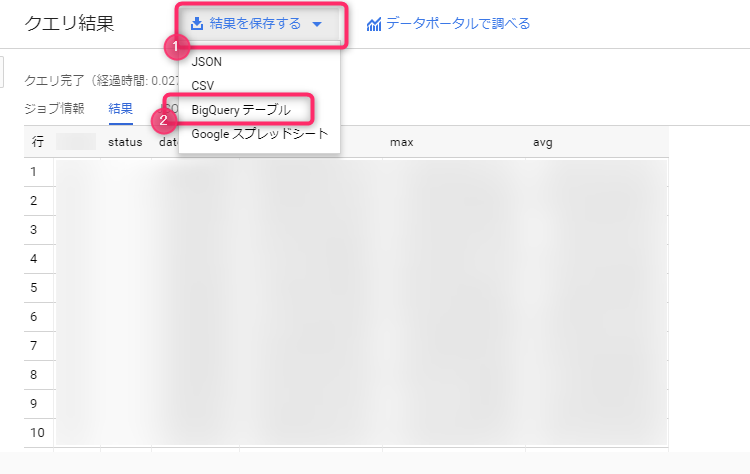
此时会弹出一个对话框,询问您是否将结果保存为表格。只需选择项目名称、数据集名称,然后输入要导出到的表格名称即可。
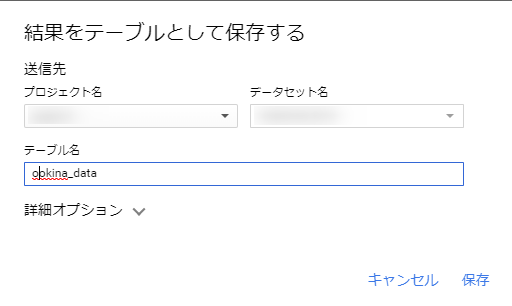
根据数据大小,可能需要一些时间,但完成后,一个新表将添加到已注册的数据集中。
该表将与正在查询的表同等对待,因此请使用导出功能将表本身导出到云存储。
在 BigQuery 中创建表时,超过 10GB 的部分将产生费用,因此在将其用于测试目的时请注意这一点。
您只需输入要导出到的 Cloud Storage 存储桶的完整路径(以存储桶名称开头),选择导出格式以及是否压缩数据,导出过程就会开始。
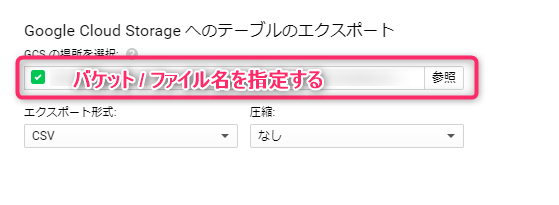
这也是一项任务,您可以查看其状态。

由于最终得到的数据量很小,因此很难捕捉到这一点。
概括
这次,我们总结了将数据从 Datastore 注册到 BigQuery 并以 CSV 格式保存到 Cloud Storage 的过程。
关键点是
- BigQuery 采用按需付费系统,价格取决于查询处理的数据量(虽然有固定费率选项,但使用不当会导致巨大损失)。
- BigQuery 的标准 SQL 与 MySQL 提供的 SQL 略有不同。
- 云存储让数据传输变得轻松
- 这只是我个人的看法,但我认为 BigQuery 很容易上手。
- 从数据存储导出到云存储所需时间出乎意料地长
我想就是这样了。
查询执行速度快,运行流畅,这项服务非常棒!
难怪它如此受欢迎。
BigQuery 有多种数据导出目标,而 Google Sheets 适合与非工程师沟通,因此在紧急情况下记住它可能很有用。
就这样。
 00
00 这篇文章的作者
关于作者


