【网页抓取入门】使用 Python 获取网站上的表格数据
2022.04.27
 9
9 
您好,很高兴见到您。
我是系统解决方案部门的河合,最近我完全迷上了 Kirby Discovery。
天气已经很热了,但春天来了!我在通勤路上开始看到不少穿着工作服、神采奕奕的新员工(虽然我已经忘了以前上班是什么样子了)。
这次,我正在写一篇关于Python网络爬虫的文章,或许能对这些新员工的工作有点帮助。
什么是刮削?
近年来,数据分析备受关注,而网络爬虫(scraping)是获取特定数据(主要来自网站)的一项基础技术。
“scrape”一词最初的意思是“收集”,似乎就是由此衍生而来。
在本文中,我们将使用编程语言 Python 自动检索页面中的表格信息。

准备
如果未安装 Python,请从官方网站下载并安装适用于您操作系统的软件包: https://www.python.org/downloads/ 。
完成后,安装我们将要使用的库“ BeautifulSoup4 ”和“ html.parser ”。
本文假设您在 Windows 环境下操作,因此请按 [CTRL] + [R] 打开命令提示符,输入 [cmd],然后执行以下命令。安装程序将开始运行。
使用 pip 安装 bs4 html.parser
这次,我想尝试从以下 Microsoft 页面自动获取 Office 365 中使用的域名和 IP 地址等信息,然后将其写入 CSV 文件(手动获取这些信息非常麻烦)。
“Office 365 URL 和 IP 地址范围” > “Microsoft 365 通用和 Office Online”
https://docs.microsoft.com/ja-jp/microsoft-365/enterprise/urls-and-ip-address-ranges?view=o365-worldwide
运行环境和完整代码
操作系统:Microsoft Windows 10 专业版;
Python 版本:3.10
from bs4 import BeautifulSoup from html.parser import HTMLParser import csv from urllib.request import urlopen headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0"} html = urlopen("https://docs.microsoft.com/ja-jp/microsoft-365/enterprise/urls-and-ip-address-ranges?view=o365-worldwide") bsObj = BeautifulSoup(html, "html.parser") table = bsObj.findAll("table")[4] rows = table.findAll("tr") with open(r"C:\Users\python\Desktop\python\2022\microsoft.csv", "w", encoding="cp932", newline="") as file: writer = csv.writer(file) for row in rows: csvRow = [] for cell in row.findAll(["td", "th"]): csvRow.append(cell.get_text()) writer.writerow(csvRow)
代码说明
from bs4 import BeautifulSoup from html.parser import HTMLParser import csv from urllib.request import urlopen
导入各个库。
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0"} html = urlopen("https://docs.microsoft.com/ja-jp/microsoft-365/enterprise/urls-and-ip-address-ranges?view=o365-worldwide") bsObj = BeautifulSoup(html, "html.parser")
→ 我们添加用户代理信息(在本例中,我们将使用 Firefox)。
我们使用 urlopen 指定要打开的页面,并在此处声明,以便 BeautifulSoup 可以读取它。
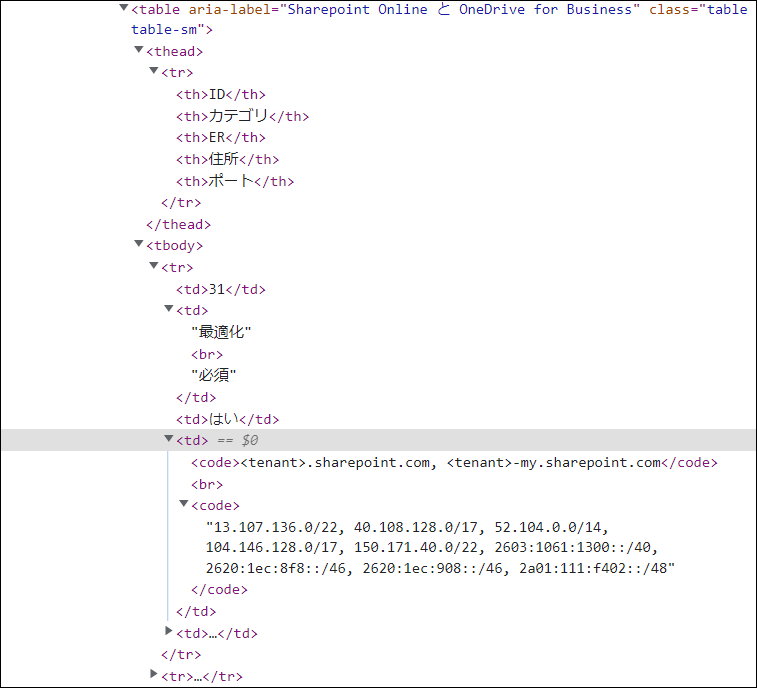
table = bsObj.findAll("table")[4] rows = table.findAll("tr")
→ 根据 HTML 结构(使用各浏览器的开发者工具),将 [4] 指定为第四个表格。此外,使用 findAll 函数查找“tr”标签。
with open(r"C:\Users\python\Desktop\python\2022\microsoft.csv", "w", encoding="cp932", newline="") as file: writer = csv.writer(file) for row in rows: csvRow = [] for cell in row.findAll(["td", "th"]): csvRow.append(cell.get_text()) writer.writerow(csvRow)
→ 指定字符代码等,以及所需的路径和文件名(如果文件不存在,则会在指定的路径中创建该文件)。
您可以使用“w”写入数据,并使用“newline=""”在每列后换行符输出检索到的信息。程序
会在上一列指定的行(tr 标签)中搜索 td 和 th,使用循环检索这些列的值,并将它们写入 CSV 文件。
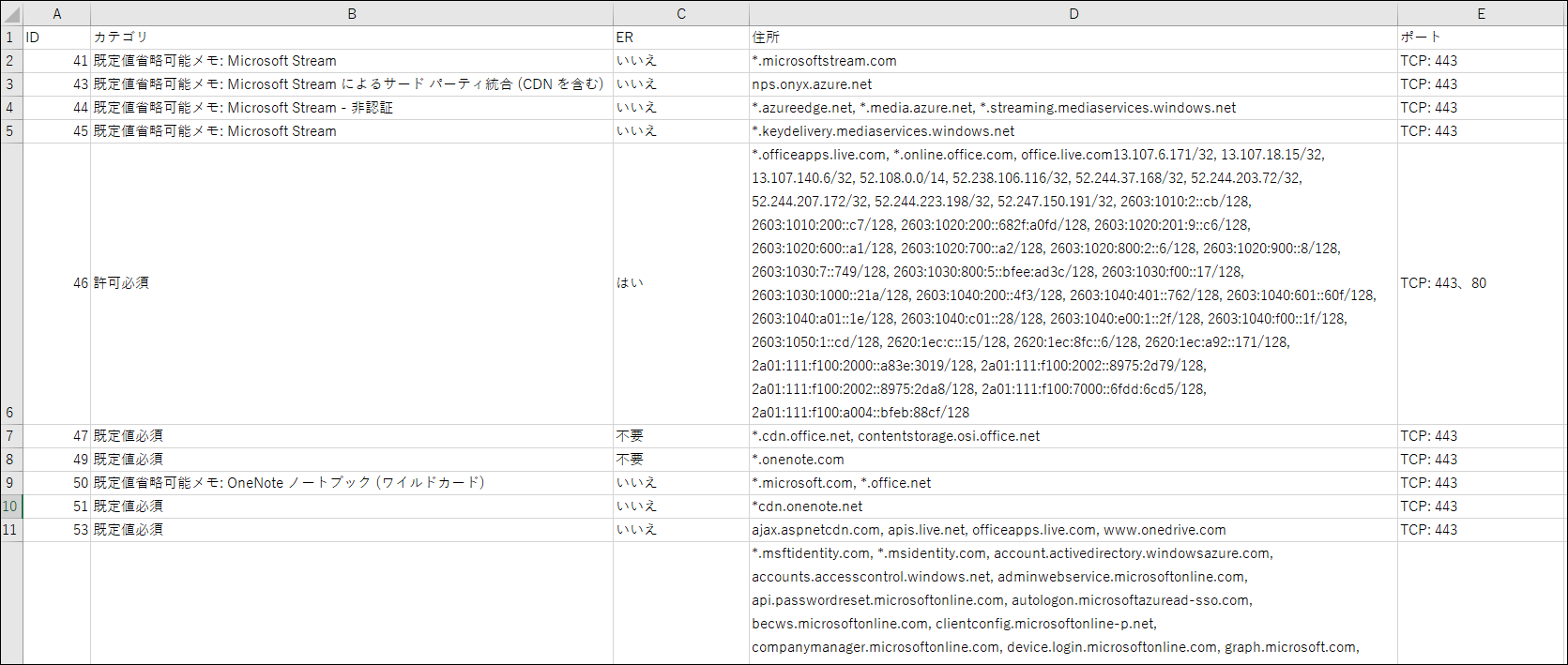
输出结果
这就是我得到的结果。这次我只得到了一些信息,但信息越多,效率就越高。
如果我还有机会,我想写一篇对别人有用的文章。
99 这篇文章的作者
关于作者


