使用 Python [pandas] 从 CSV 文件中聚合特定时期的数据

您好,
我是系统解决方案部门的川。我怀揣着远大的梦想,但性格却很软弱。
天气越来越暖和了,不是吗?
所以,这次我将使用 pandas,一个基本的 Python 数据分析库,
来聚合来自 CSV 文件的大量数据。
环境
操作系统:Microsoft Windows 10 专业版;
Python 版本:3.10.4
大局
import pandas as pd from datetime import datetime as dt import collections import itertools df = pd.read_csv('<filename>.csv', usecols=['datetime', 'person_in_charge'], encoding='cp932' ) df_date = df.set_index('datetime') # 用于错误检查 def check(x): #print(x) pd.to_datetime(x) df_date.index.map(check) df_date.index=pd.to_datetime(df_date.index,format='%Y%m%d %H:%M') df_date.sort_index(inplace=True) df_date['count'] = 1 df_multi = df_date.set_index([df_date.index.year, df_date.index.month, df_date.index.weekday, df_date.index.hour, df_date.index]) df_multi.index.names = ['year', 'month', 'weekday', 'hour', 'date'] df_date['person_in_charge'] = df_date['person_in_charge'].str.split(',') all_tag_list = list(itertools.chain.from_iterable(df_date['person_in_charge'])) c = collections.Counter(itertools.chain.from_iterable(df_date['person_in_charge'])) tags = pd.Series(c) df_tag_list = [] top_tag_list = tags.sort_values(ascending=False).index[:11].tolist() for t in top_tag_list: df_tag = df_date[df_date['person_in_charge'].apply(lambda x: t in x)] df_tag_list.append(df_tag[['count']].resample('1M').sum()) df_tags = pd.concat(df_tag_list, axis=1) df_tags.columns = top_tag_list df_tags.to_csv('result.csv', encoding='cp932') print("完成")
目的和准备
包含大量信息
,包括查询接收日期(yyyy/mm/dd 格式)和查询作为预处理步骤,日期列名设置为“datetime”,负责人姓名设置为“person_in_charge”。
由于 pandas 是以库的形式使用,因此必须
通过 pip 安装 (对于其他环境,例如 Anaconda,请参阅链接。)
部分解释
▼ 使用 pandas 读取文件。csv 文件与代码文件位于同一文件夹中。
df = pd.read_csv('<filename>.csv', usecols=['datetime', 'person_in_charge'], encoding='cp932' )
▼ 使用 df.set_index 将“datetime”列分配给索引。
*后半部分只是检查是否有空白单元格,因此可以省略。
df_date = df.set_index('datetime') def check(x): pd.to_datetime(x) df_date.index.map(check)
▼ 将数据类型转换为日期时间格式并排序
df_date.index=pd.to_datetime(df_date.index,format='%Y%m%d %H:%M') df_date.sort_index(inplace=True) #添加一个计数列用于重采样 df_date['count'] = 1
▼按日期或时间分组和计数
df_multi = df_date.set_index([df_date.index.year, df_date.index.month, df_date.index.weekday, df_date.index.hour, df_date.index]) df_multi.index.names = ['year', 'month', 'weekday', 'hour', 'date'] df_date['person_in_charge'] = df_date['person_in_charge'].str.split(',') all_tag_list = list(itertools.chain.from_iterable(df_date['person_in_charge'])) # 将迭代结果传递给集合。统计每个标签出现的次数 c = collections.Counter(itertools.chain.from_iterable(df_date['person_in_charge'])) # 转换为序列 tags = pd.Series(c)
▼ 将标签存储在 DataFrame 中
df_tag_list = [] top_tag_list = tags.sort_values(ascending=False).index[:11].tolist()
▼ 这是关键所在。如果您将“df_tag_list.append(df_tag[['count']].resample('1M').sum())”中的“'1M'”部分更改
为“'2W'”,则可以每两周聚合一次数据;或者更改为“'7D'”,则可以每七天聚合一次数据。
for t in top_tag_list: df_tag = df_date[df_date['person_in_charge'].apply(lambda x: t in x)] df_tag_list.append(df_tag[['count']].resample('1M').sum()) df_tag_list = pd.concat(df_tag_list, axis=1) df_tags.columns = top_tag_list
▼ 将汇总数据输出到新文件
df_tags.to_csv('result.csv', encoding='cp932') #完成后,打印“done” print("done")
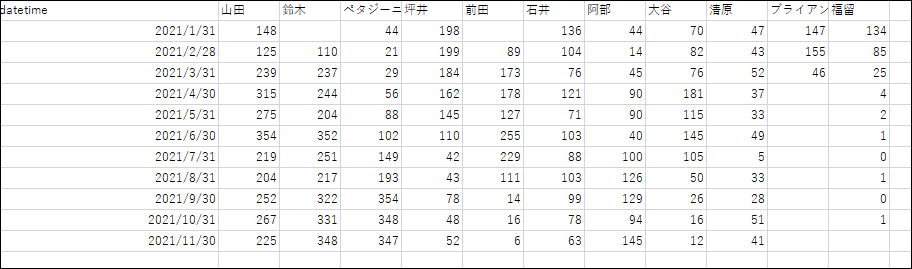
输出结果
好了,这就是
每个负责人的月度汇总数据。您还可以根据需要按周或按日汇总数据,而且
通过一些巧妙的样式设置,您甚至可以将其用作会议数据!
回头见!
如果您觉得这篇文章有用,请点击【点赞】!
 66
66
2,503
这篇文章的作者
关于作者


