![[Osaka/Yokohama/Tokushima] Looking for infrastructure/server side engineers!](https://beyondjapan.com/cms/wp-content/uploads/2022/12/recruit_blog_banner-768x344.jpg)
[Osaka/Yokohama/Tokushima] Looking for infrastructure/server side engineers!
![[Deployed by over 500 companies] AWS construction, operation, maintenance, and monitoring services](https://beyondjapan.com/cms/wp-content/uploads/2021/03/AWS_構築・運用保守-768x344.png)
[Deployed by over 500 companies] AWS construction, operation, maintenance, and monitoring services
![[Successor to CentOS] AlmaLinux OS server construction/migration service](https://beyondjapan.com/cms/wp-content/uploads/2023/08/almalinux_blogbanner-768x344.png)
[Successor to CentOS] AlmaLinux OS server construction/migration service
![[For WordPress only] Cloud server “Web Speed”](https://beyondjapan.com/cms/wp-content/uploads/2022/11/webspeed_blog_banner-768x344.png)
[For WordPress only] Cloud server “Web Speed”
![[Cheap] Website security automatic diagnosis “Quick Scanner”](https://beyondjapan.com/cms/wp-content/uploads/2023/04/quick_eyecatch_blogbanner-768x345.jpg)
[Cheap] Website security automatic diagnosis “Quick Scanner”
![[Reservation system development] EDISONE customization development service](https://beyondjapan.com/cms/wp-content/uploads/2023/06/edisone_blog_banner-768x345.jpg)
[Reservation system development] EDISONE customization development service
![[Registration of 100 URLs is 0 yen] Website monitoring service “Appmill”](https://beyondjapan.com/cms/wp-content/uploads/2021/03/Appmill_ブログバナー-768x344.png)
[Registration of 100 URLs is 0 yen] Website monitoring service “Appmill”
![[Compatible with over 200 countries] Global eSIM “Beyond SIM”](https://beyondjapan.com/cms/wp-content/uploads/2024/05/beyond_esim_blog_slider1-768x345.jpg)
[Compatible with over 200 countries] Global eSIM “Beyond SIM”
![[If you are traveling, business trip, or stationed in China] Chinese SIM service “Choco SIM”](https://beyondjapan.com/cms/wp-content/uploads/2024/05/china-sim_blogbanner-768x345.jpg)
[If you are traveling, business trip, or stationed in China] Chinese SIM service “Choco SIM”
![[Global exclusive service] Beyond's MSP in North America and China](https://beyondjapan.com/cms/wp-content/uploads/2024/06/gloval_surport_blog_slider-768x345.jpg)
[Global exclusive service] Beyond's MSP in North America and China
![[YouTube] Beyond official channel “Biyomaru Channel”](https://beyondjapan.com/cms/wp-content/uploads/2021/07/バナー1-768x339.jpg)
[YouTube] Beyond official channel “Biyomaru Channel”
[RDB] Overview and features of Cloud Spanner [Global database]

table of contents
This is Ohara from the technical sales department.
we will provide an overview and features of Cloud Spanner provided by Google Cloud
Overview and features of Cloud Spanner
Cloud Spanner is a powerful, fully managed relational database service.
Provides automatic synchronous replication for transactional consistency, schema, SQL (ANSI 2011 and extensions), high availability, and disaster recovery (DR) on a global scale.
An enterprise-grade, globally distributed, highly consistent database service built for the cloud that takes the benefits of a relational database structure and scales horizontally to thousands of non-relational nodes.
Cases for using Cloud Spanner
Case scenarios for using CloudSpanner are:
● You have relational data that requires strong consistency.
● You require high availability through data replication
. ● You need multi-region deployment of your database.
● You need high scalability (start small and scale as needed. It is possible to increase scale quickly and exceed the scale limitations of traditional relational OLTP systems.
Cloud Spanner architecture
Cloud Spanner is a global database and offers two types of configurations: regional and multi-regional.
To logically partition your data and facilitate proper replication and sharding of your data, CloudSpanner uses instances and databases.
① Instance and database
instance refer to the resource allocation used by the Cloud Spanner database created on that instance.
Creating an instance consists of two important choices: instance configuration and number of nodes.
An instance configuration defines the geographic placement and replication of databases within that instance.
A database is a collection of tables within an instance.
Cloud Spanner's database maintains tables and indexes that allow you to read and write data.
An instance can have multiple databases.
● Regional instance
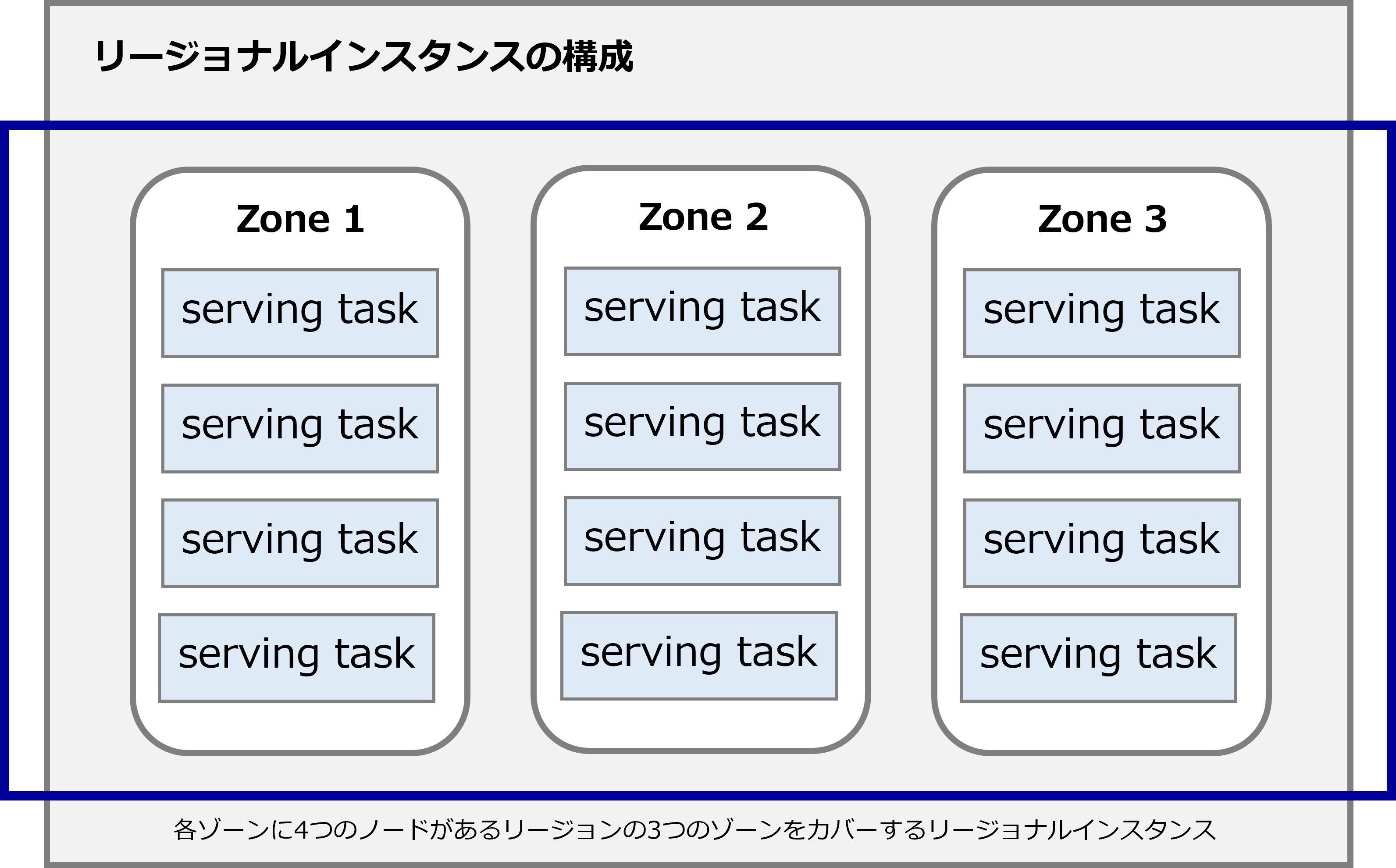
A regional instance spans a single Google Cloud region.
In a regional instance configuration, Cloud Spanner three read/write replicas , each in a different Google Cloud zone in the region.
Each read/write replica contains a complete copy of the production database that can handle read/write and read-only requests.
Cloud Spanner uses replicas in different zones, so your database remains available even in the event of a single zone failure.
● Multi-regional instance
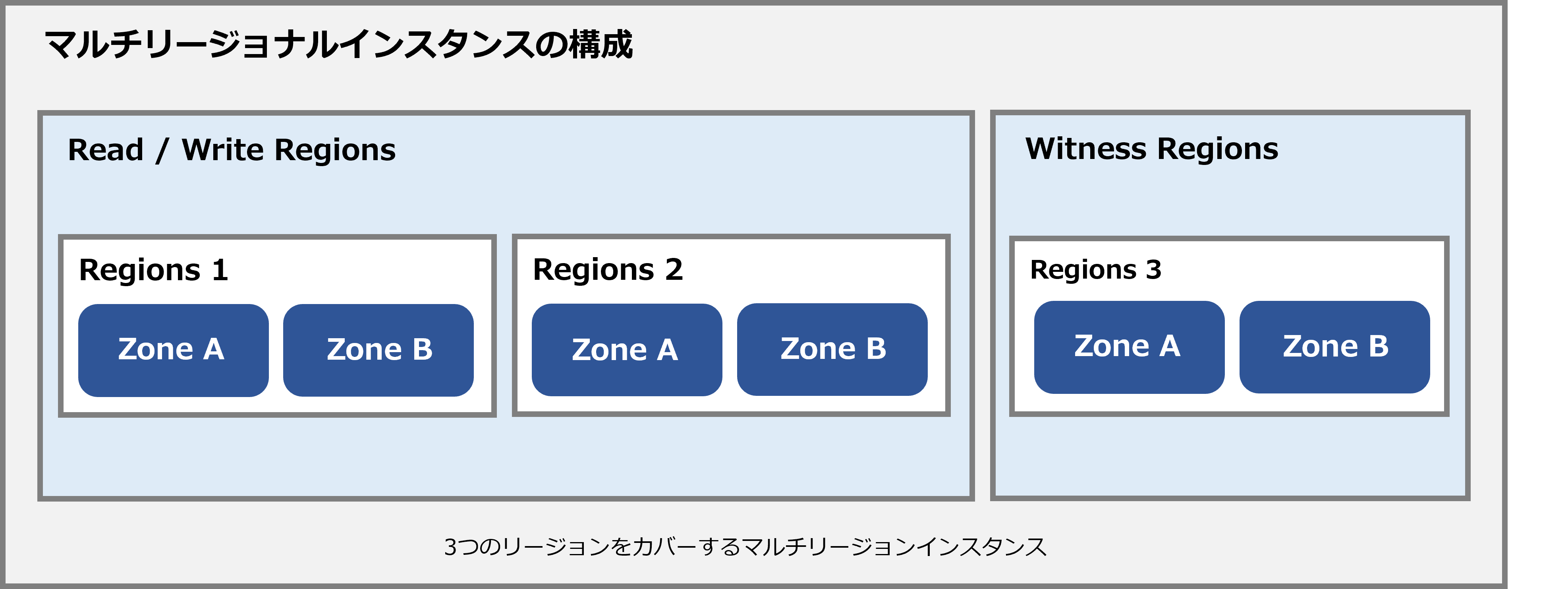
A multi-region configuration allows you to replicate data in your database to multiple zones, as well as multiple zones across multiple regions, as defined in your instance configuration.
These additional replicas allow you to read data with low latency from multiple locations near or within the region in your configuration.
Multi-region instances are useful if you have an application that needs to read data from multiple geographical locations because it allows your application to achieve faster reads in more locations at the cost of a slight increase in write latency. Very useful in case.
Each multi-region configuration includes two regions designated as read/write regions contains read/write replicas One of these read/write areas is designated as the default reader area. (meaning it contains the database's leader replica)
* In a multi-region configuration, the quorum (read/write) replicas are distributed across multiple regions, which comes with trade-offs, such as the potential for additional network latency as these replicas communicate with each other and vote for writes. There is. (Cloud Spanner requires commits to be persisted in at least two different regions, which increases commit latency)
② High-level architecture
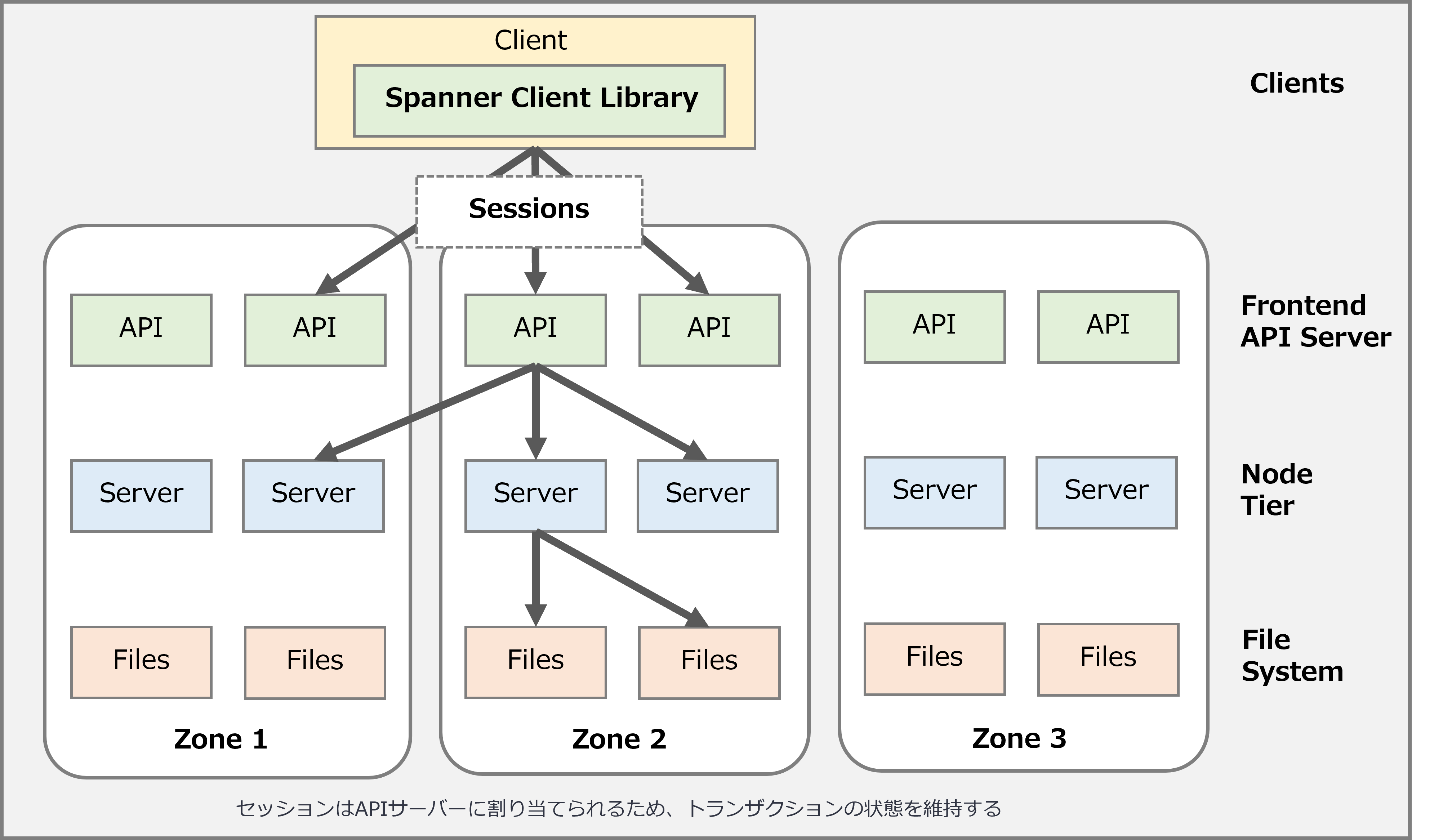 Simply put, Cloud Spanner's functionality is primarily supported by
Simply put, Cloud Spanner's functionality is primarily supported by
the API server You use sessions the Cloud Spanner client library execution environment (Each session is associated with a single database and can only run one transaction at a time)
Sessions are assigned to the API server so that transactional state can be maintained.
API servers are not deployed at the zone or region level, but can be shared across regions and can be multi-regional.
Based on the API request, the API server determines which node server to contact to complete the request.
A node server is a node that you assign to an instance and performs most of the work.
Node servers handle read and write/commit transaction requests, but do not store data.
Data is stored in Google's underlying distributed file system provided by other storage nodes.
summary
My impression of using Cloud Spanner is that if you are a globally expanding company (company with data in each country) that requires consistent data processing with low network latency, you should use Cloud Spanner. Looks like it's worth seeing.
 00
00 ![[2025.6.30 Amazon Linux 2 support ended] Amazon Linux server migration solution](https://beyondjapan.com/cms/wp-content/uploads/2024/05/59b34db220409b6211b90ac6a7729303-1024x444.png)
[2025.6.30 Amazon Linux 2 support ended] Amazon Linux server migration solution
The person who wrote this article
About the author
