Perfect for studying over the New Year holidays! Loading and analyzing Datastore data into GCP BigQuery

table of contents
Hello,
I'm Mandai, the Wild Team member of the development team.
I wanted to analyze the monitoring data from Appmill, but the amount of data was getting so large that it was becoming difficult to store it in the database.
When it comes to GCP, that's it.
Yes, that's where BigQuery comes in
This time, we will show you how to import Datastore data on GCP into BigQuery, run queries on it, and export it for reuse
Preparing to load data from Datastore
First, please note that you cannot import data directly from Datastore to BigQuery
Therefore, we first move the data from Datastore to Cloud Storage
To move Datastore data to Cloud Storage, use the Datastore backup function.
Prepare a bucket in Cloud Storage beforehand to store the backup.
As explained later, we recommend creating the bucket in the Tokyo region (asia-northeast1).
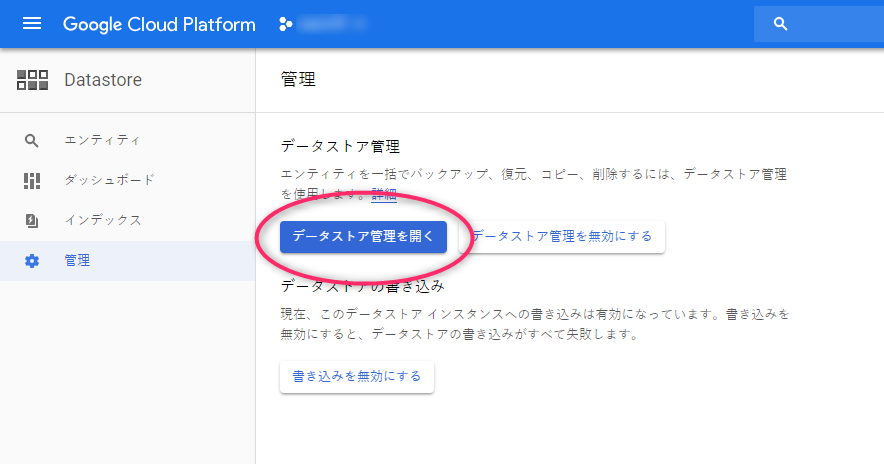
There is an item called "Management" in the Datastore menu, so select that
Next, there is a button that says "Open Data Store Management." Click on it.
Please note that there is a lot of mosaic content because this is a capture of real data.
You will be asked to confirm only the first time you run the program, but a separate window will open and display a list of the data sizes for each kind in the Datastore in the selected project
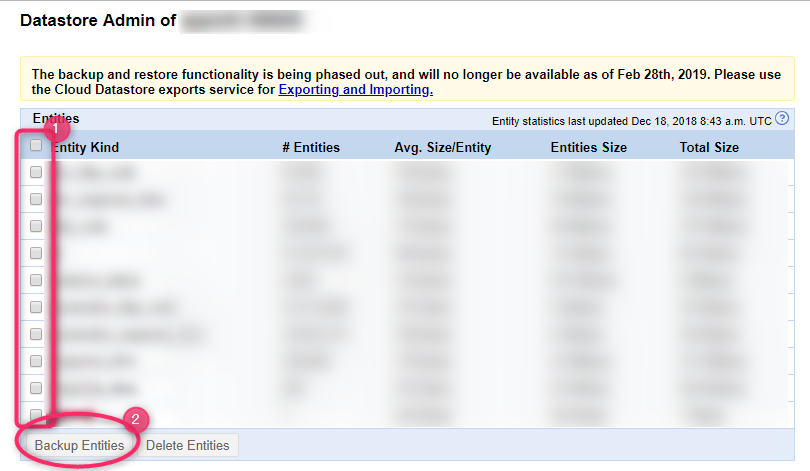
Check the Kind of entity you want to extract and click "Backup Entities" to start the backup.
The export will not finish immediately, so please wait a while.

Try reloading it a few times, and once you see the screen above, it's complete
Registering data in BigQuery
Once the data preparation is complete, we load it into BigQuery.
Since the UI has been updated, I'll be including lots of screenshots (sorry for the blurred background).
Once you are on the BigQuery screen, click the "Add Data" link under the "Resources" section in the left menu.
Select "Specify project" and select the Cloud Storage project ID where you saved your Datastore data.

If the specified project appears below the search box as shown below, you have succeeded

Next, create a dataset in the project.
Click on the project ID you just added.
The right pane will switch to the query editor.
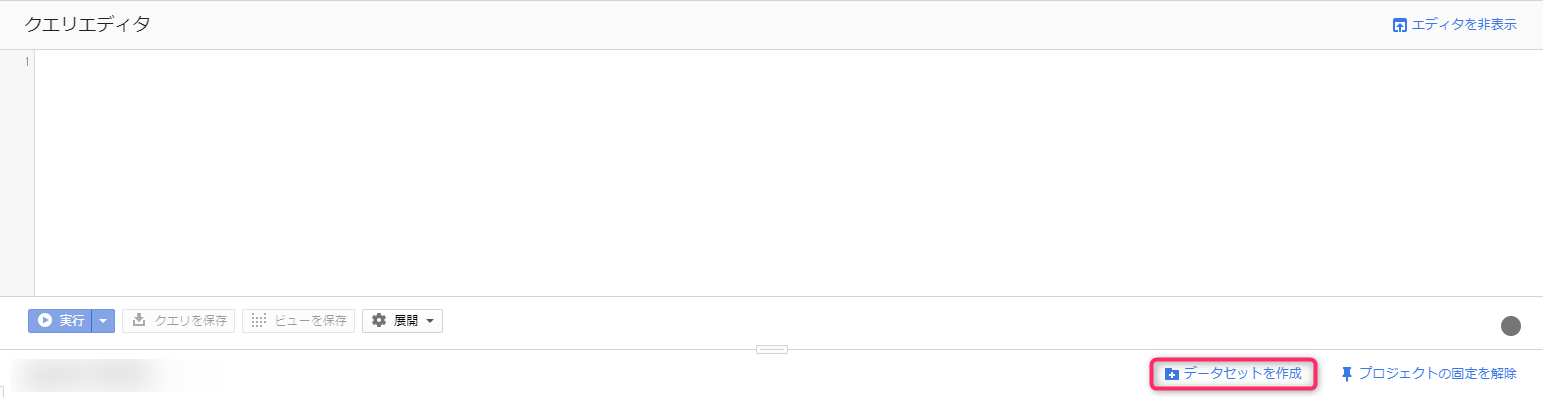
Below the query editor, there is a link called "Create dataset." If you click on it, the dataset creation screen will pop up from the right
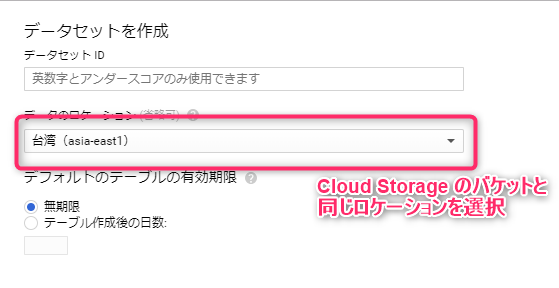
Enter a dataset ID that will allow you to easily identify the data you are about to input, and select the location of the data.
The important thing about the location is that it must match the region where the Cloud Storage bucket you created first is located.
If you create a Cloud Storage bucket in the Tokyo region, you would select asia-northeast1.
If you created BigQuery data in a multi-region, the Cloud Storage bucket can be in a location within the selected multi-region.
At the time of writing, BigQuery only supports two multi-region options: US and EU; ASIA is not available.
If you followed this article, you will have created a Cloud Storage bucket in asia-northeast1, so you will also have to create a BigQuery dataset in asia-northeast1
Once you have created the dataset, you can then create a table
A tree with the dataset you just created hanging below the project ID on the left will be created, so now click on the dataset name
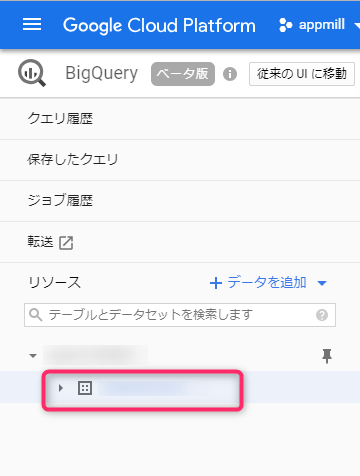
The right pane will then switch and a link called "Create Table" will appear, so click on it
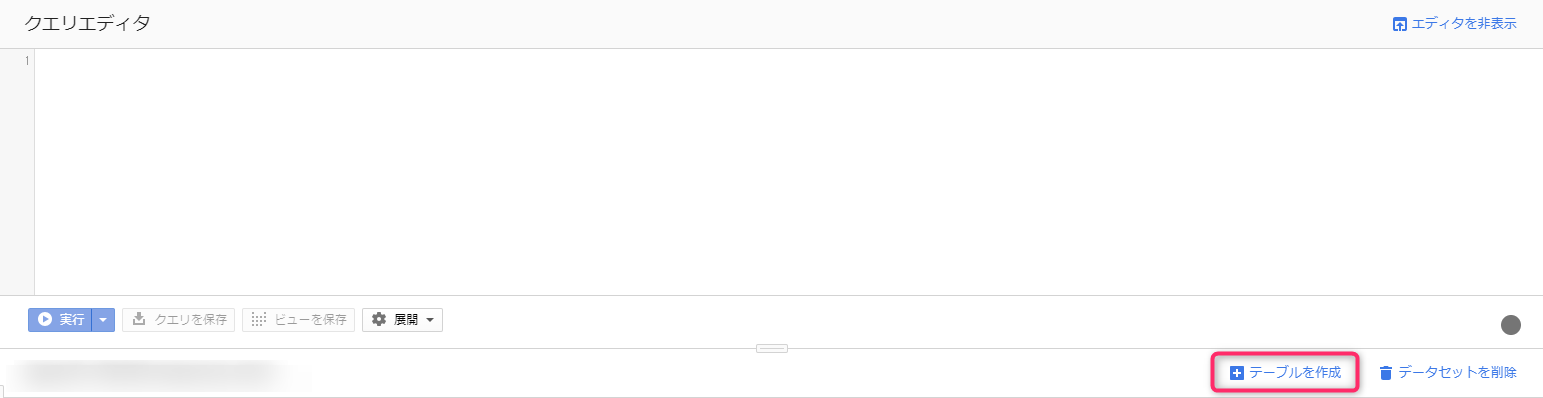
There are many input fields, but we will explain each one!
- Table created by
- Choose where to get the data from. If you choose upload, the uploader will appear. In this example, select Cloud Storage
- Select a file from a GCS bucket
- Enter the path to the file with the extension ".[Datastore Entity Kind].backup_info" from the Cloud Storage bucket name. You can also browse through the directory tree, but since the file name of the .backup_info file is too long and gets cut off, we recommend copying and pasting it from the Cloud Storage screen, even though it is a hassle
- File formats
- Select Cloud Datastore Backup
- Project Name
- For this step, it is already selected
- Dataset Name
- For this step, it is already selected
- Table Name
- Give it a name that will make it easy to identify within the dataset
Other items do not need to be changed unless there are special requirements
Once you press the Create button, a data loading job will be created and added to the job history
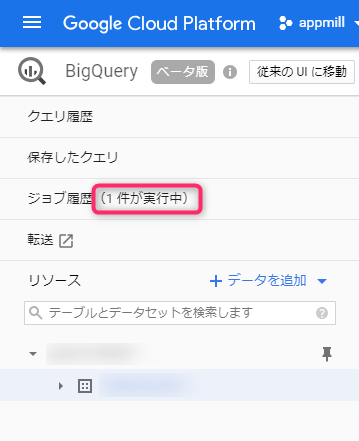
Once the job is complete and the table is populated with data, you're ready to run queries
Execute the query
Before executing a query, let's write it in the editor

In the image above, an error occurs because a dataset and table that do not exist are specified.
However, the queries that can be written here are designed to allow standard SQL queries to be written.
For the table name after "from", specify the dataset name and table name connected by a dot.
If you specify an existing dataset and table, it will look like this:
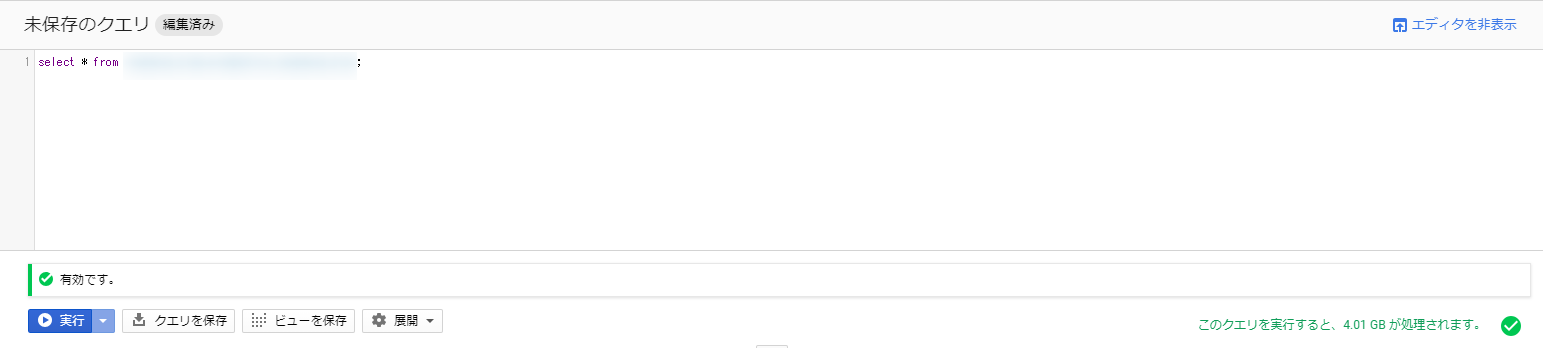
The part to pay attention to is the bottom right, which shows the size of the data output as a result of the search.
As this part increases, the cost of executing the query increases.
As of December 19, 2018, it's $5 per 1TB, so you can use it without worrying too much.
Also, there's a free quota of 1TB per month, which I think is enough to try it out.
With the data used in this test, 4.01GB of data was processed, which means that you can run the query approximately 250 times for free.
Also, the same query is cached for 24 hours, so it is not recalculated and no charges are incurred.
Make full use of the generous free quota and get used to using even small amounts of data!
BigQuery now comes with standard SQL compatible with SQL 2011, so even those who have only used MySQL or PostgreSQL can get started easily.
However, there are still some things that you can do with MySQL that I would like to introduce in a separate article.
Export the results
If you want to move the resulting data somewhere, it's convenient to export the results
Here we will show you how to export the execution results to CSV and store them in Cloud Storage
There are several ways to export the results of a query, but if the result set is small, exporting it directly to CSV and downloading it is easy and time-saving.
Other options include JSON if you plan to use it in a program, or Google Spreadsheets if your company uses G Suite.
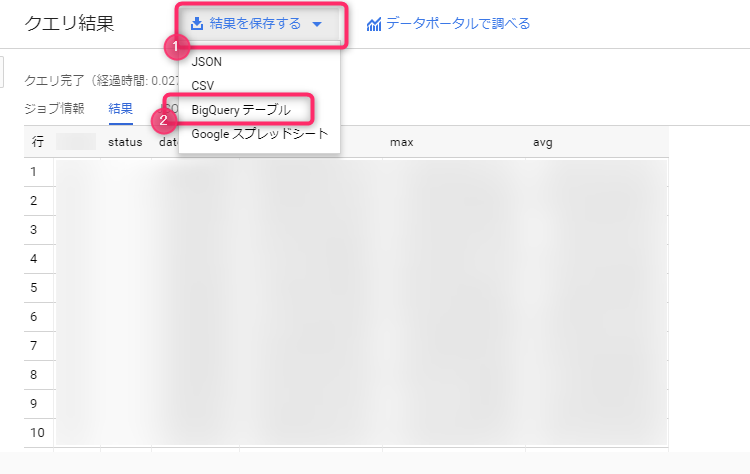
However, if the result set becomes large, you will need to export it to a BigQuery table first, as you will only be able to download the first part

To save a large result set to a BigQuery table, select BigQuery Table from "Save results as" next to the query result title
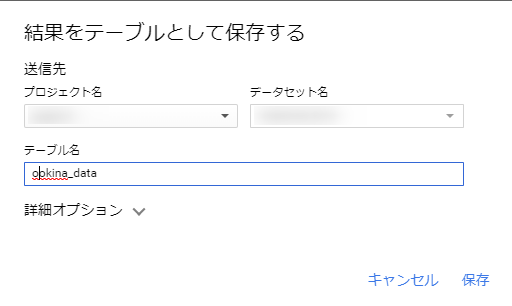
A modal will appear asking you to save the results as a table. Simply select the project name, dataset name, and enter the name of the table to export to
It may take some time depending on the data size, but once it's complete, a new table will be added to the registered dataset.
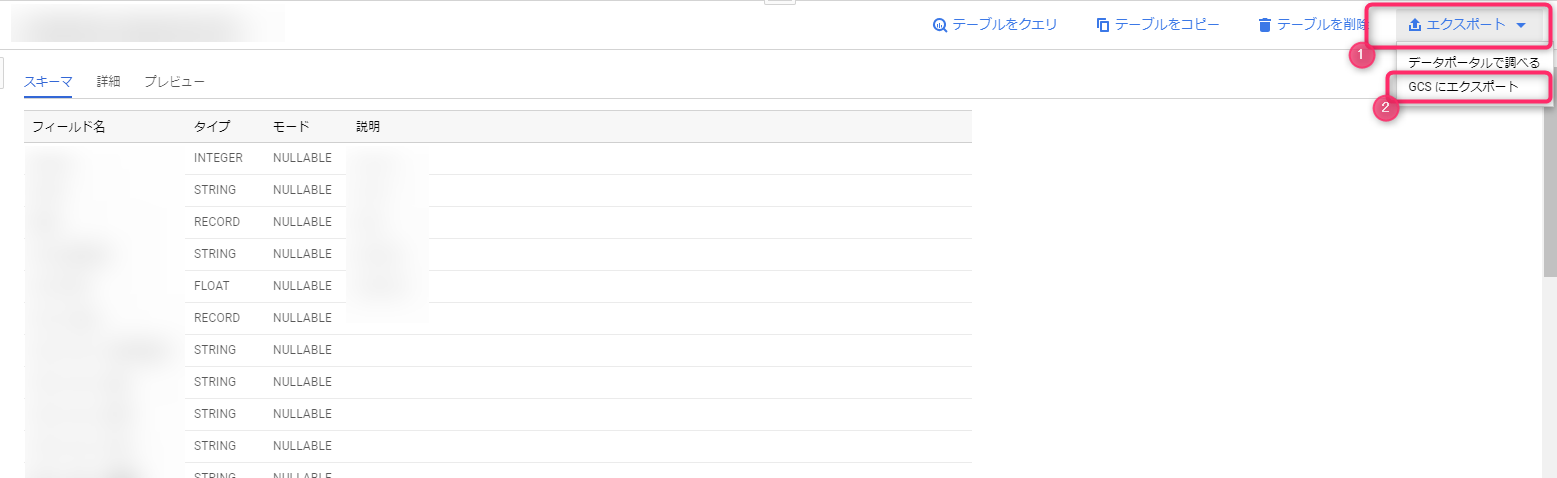
This table will be treated the same as the table being queried, so use the export function to export the table itself to Cloud Storage.
When creating a table in BigQuery, charges will be incurred for any portion exceeding 10GB, so please be aware of this when using it for testing purposes.
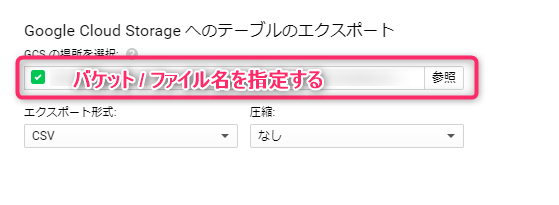
All you have to do is enter the full path starting with the name of the Cloud Storage bucket to which you want to export, select the export format and whether or not to compress the data, and the export will begin
This is also managed as a job and you can check the status

It was difficult to capture this because the resulting data size was small
summary
This time, we have summarized the process of registering data from Datastore to BigQuery and saving it in Cloud Storage in CSV format
The key points are
- BigQuery is a pay-as-you-go system where the price is determined by the amount of data processed by the query (there is a flat rate option, but careless use will result in a huge loss)
- BigQuery's standard SQL is slightly different from that provided by MySQL
- Cloud Storage makes data transfer easy
- This is just my personal opinion, but I think BigQuery is easy to use
- Exporting from Datastore to Cloud Storage takes a surprisingly long time
I guess that's it
Query execution times are fast and stress-free, making it a great service!
It's no wonder it's so popular.
There are various destinations available for exporting data from BigQuery, and Google Sheets is suitable for communicating with non-engineers, so it may be useful to remember it in case of emergency
That's all
 00
00 The person who wrote this article
About the author


